 异常教程
异常教程
文本集群:美国总统写国情咨文,反之亦然?
💡一则或许对你有用的小广告
欢迎加入小哈的星球 ,你将获得:专属的项目实战(已更新的所有项目都能学习) / 1v1 提问 / Java 学习路线 / 学习打卡 / 每月赠书 / 社群讨论
- 新开坑项目:《Spring AI 项目实战》 正在持续爆肝中,基于 Spring AI + Spring Boot 3.x + JDK 21..., 点击查看 ;
- 《从零手撸:仿小红书(微服务架构)》 已完结,基于
Spring Cloud Alibaba + Spring Boot 3.x + JDK 17...,点击查看项目介绍 ;演示链接: http://116.62.199.48:7070 ;- 《从零手撸:前后端分离博客项目(全栈开发)》 2 期已完结,演示链接: http://116.62.199.48/ ;
截止目前, 星球 内专栏累计输出 100w+ 字,讲解图 4013+ 张,还在持续爆肝中.. 后续还会上新更多项目,目标是将 Java 领域典型的项目都整一波,如秒杀系统, 在线商城, IM 即时通讯,权限管理,Spring Cloud Alibaba 微服务等等,已有 3700+ 小伙伴加入学习 ,欢迎点击围观
在这篇文章中,我将文本聚类技术—— 层次聚类 、 K-均值 和 主成分分析 ——应用于从杜鲁门到奥巴马的每一个总统州的演讲。我使用 R 进行设置、聚类和数据可视化。

原来国情咨文比总统写国情咨文还多。演讲中使用的词语似乎与时代有关,而不是与总统个人或其党派关系有关。然而,乔治·W·布什总统有一个主要例外,其风格和内容与他的前任和同时代的人都大相径庭。您可以 在此处 查看 R 脚本和有关该过程的更多技术细节。 此处 提供截至 2007 年的国情咨文地址,其余地址可 在此处 获取。
型号:TF-IDF
建模的第一步是创建文档术语矩阵,其中文档作为行,单个单词沿列,频率计数作为内容。 Corpus 对象在标记化过程中自动填充术语元数据。但是,需要手动将文档名称导入到矩阵的元数据中。
从文档术语矩阵,可以创建一个术语频率 - 逆向文档频率矩阵。这个对象是一个与上面的文档词频矩阵相同维度的矩阵,除了每个频率已经被归一化为整个文档中的词频。这为给定文档中常见但在整个语料库中相对罕见的术语提供了额外的权重。同时,对于任何单个文档,在许多或所有文档中通用的术语在频率上受到惩罚,因为它们提供了关于给定文档的较少量的独特信息。
计算出频率后,所有文档的方矩阵将被处理为聚类的距离查找。文档有大量的术语,这意味着距离存在于非常高的维度空间中。正是出于这个原因,距离被计算为余弦相似度而不是正常的欧氏距离。
文本聚类
完成一些 设置 后,我研究了三个模型,并在此过程中进行了一些数据可视化以获得快速洞察。
模型:层次聚类
第一个模型是层次聚类,它显示了各级聚类之间的凝聚力,因为层次方法保留了所有中间聚类。我使用 Ward 聚类方法在过程的每个步骤中对形成的聚类的凝聚力施加了很大的影响。目标是学习有关文档组的隐式特征。
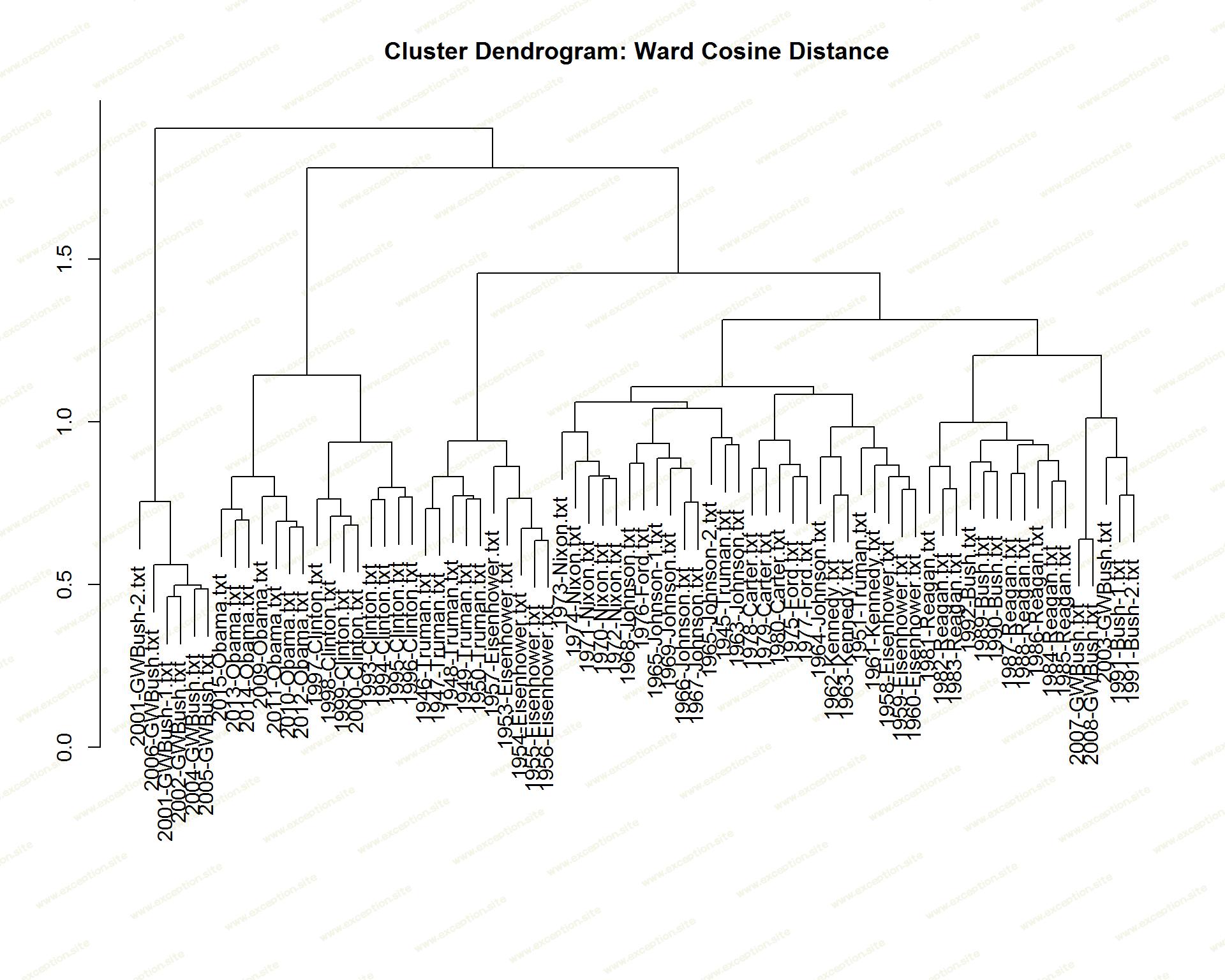
从这个聚类树状图中,第一个模式是显而易见的,正如人们所期望的那样:
-
同一位总统发表的讲话几乎总是最先出现的。
-
来自同一政党和时代的演讲通常紧挨着集群(奥巴马和克林顿、里根和老布什、艾森豪威尔和杜鲁门)
-
乔治·W·布什 (George W. Bush) 的 6 次演讲中有一组潜在的异常值,它们是最后与任何其他演讲合并的,尽管他的演讲的平衡集中在老布什和里根的演讲中。
为了进一步定义集群,我接下来研究了集群内聚性,以了解在何处“砍树”是有意义的。
这条曲线显示随着树从 20 个簇被切割到接近有文档的簇数(即每个文档在其自己的簇中),预期的逐渐下降。理想情况是拥有尽可能少的集群,以便每个集群内的平均余弦距离最小化,表明最大的集群内聚性。在计算出接近 40 个簇之前,在大约 5 个簇处有一个局部最小值,在凝聚力方面不会超过该最小值。
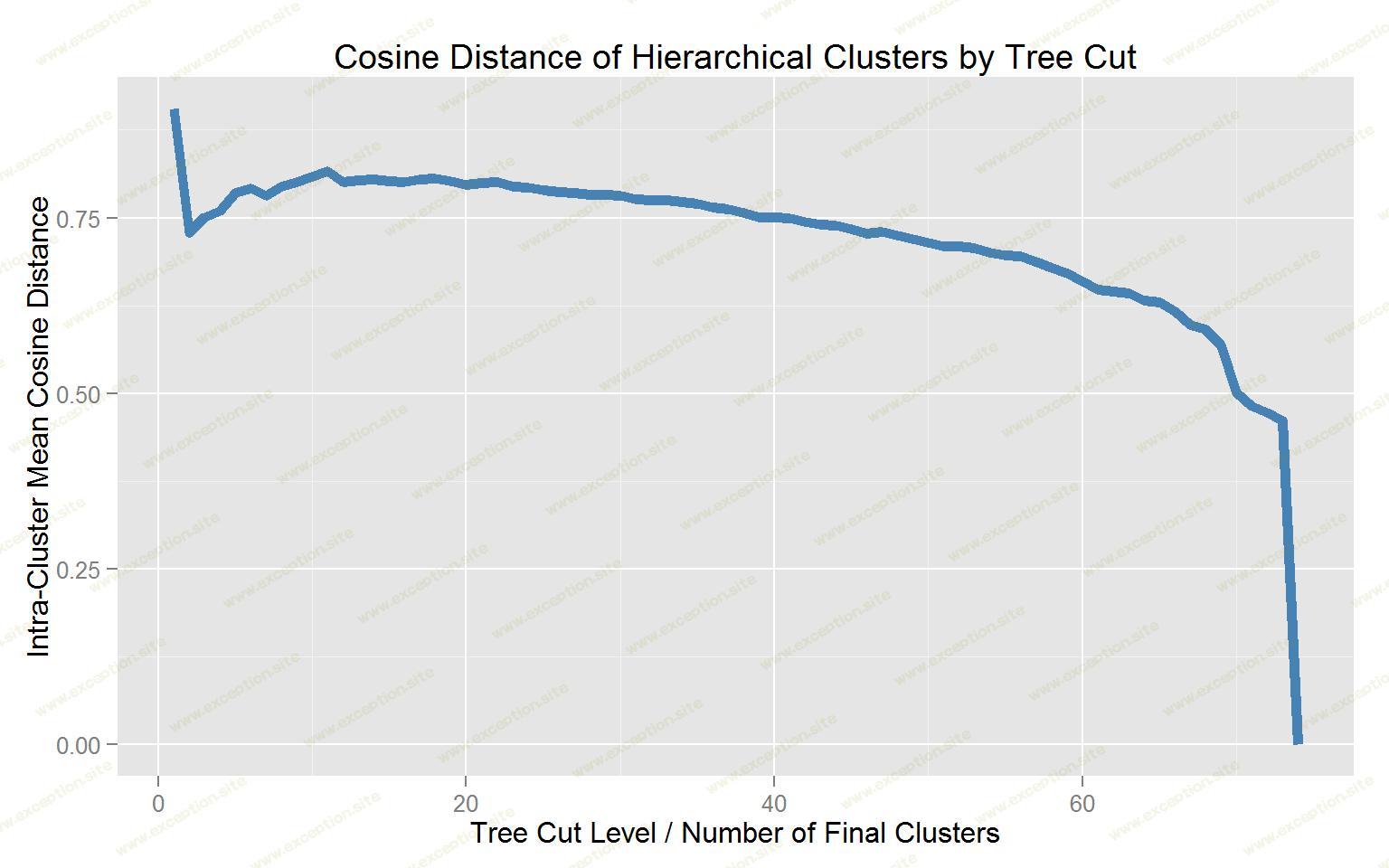
产生大约 5 个簇的切割导致每个簇大约 15-18 个文档,这似乎是与更高切割水平的可靠平衡。让我们来看看 5 个集群,看看我们看到了什么。
模型:K-Means 聚类和主成分分析
为了测试层次聚类分析,我使用了 K-Means 聚类分析来提供更直观的聚类空间表示。 K-Means 依赖于欧几里得距离而不是余弦相异性,首先需要对 TF-IDF 矩阵进行归一化。 K-Means 过程本身将为 5 个质心聚类,并将最大迭代次数从默认的 10 增加到 25。您可以 在此处 查看详细信息。
数据包含数千个维度,每个维度对应一个唯一的单词。尽管聚类是使用全维特征空间构建的,但可视化这么多维度是不切实际的。为了使可视化更容易接受,我应用了主成分分析来找到两个最重要的维度。

许多相同的模式是显而易见的。乔治·W·布什 (George W. Bush) 的 6 次相同演讲与同一时代和同一党派的其他演讲之间的距离很明显。也很容易看到政党和时代之间相同的早期集群。但是,此可视化使该上下文更进一步。除了 George W. Bush 的演讲之外,尽管模型中没有日期数据(它在加载中被删除)步)。因此,国情咨文的内容似乎在很大程度上是由它所反映的时代驱动的,而不是总统赋予它的政治联系。
深层发掘
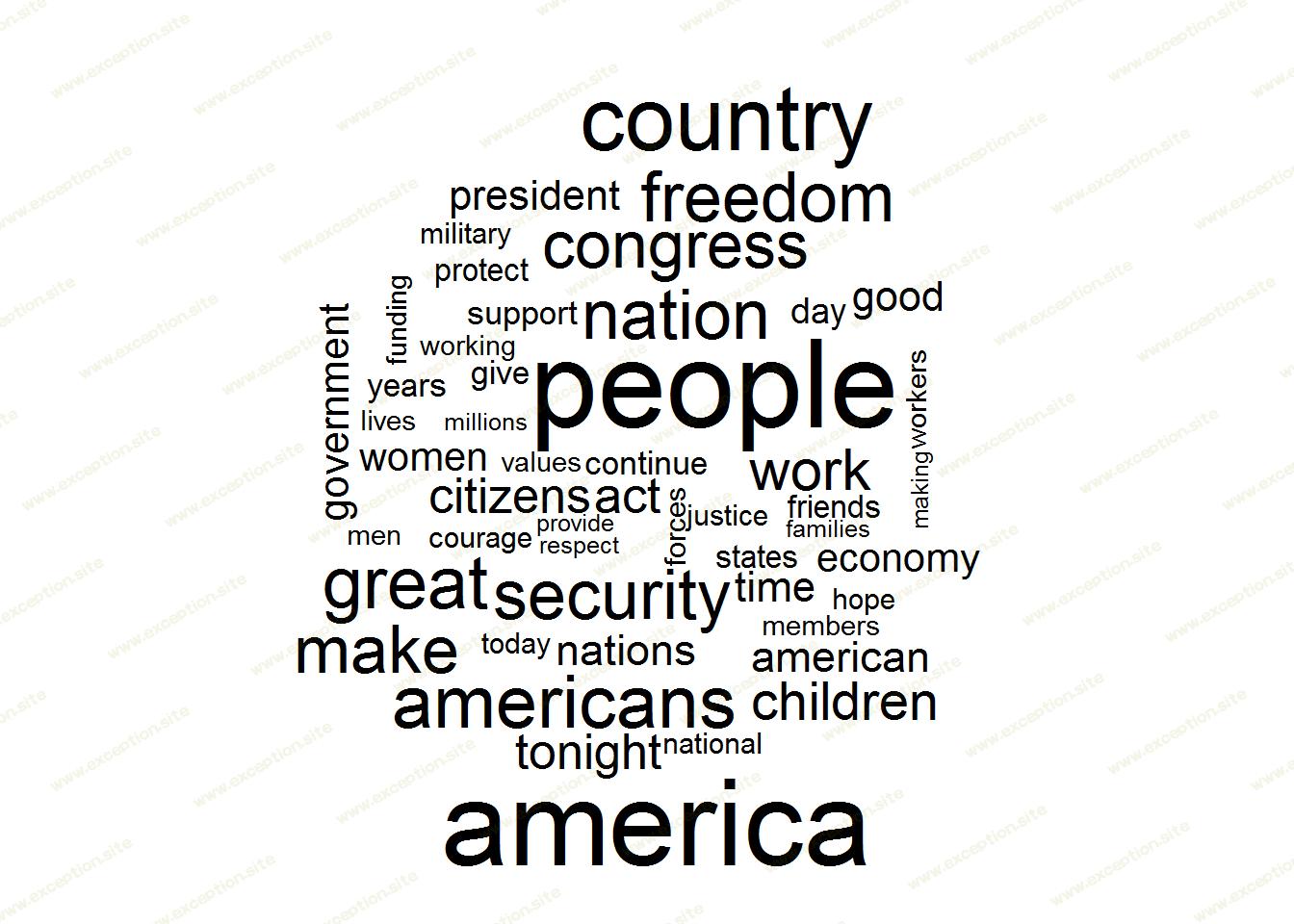
为了更深入地挖掘底层驱动因素,我想了解对每个集群最重要的常用术语。一种简单有效的方法是词云。您可以 在此处 查看 R 脚本。
所有演讲中通用的术语不足为奇。它们是总统爱国主义和政治民粹主义的主要术语。

频谱与异常值 :检查大范围内最常见的词表明,“世界”一词的使用更加受重视,许多其他术语也出现在类似的容量中。

当我将二战后的场景(第 4 组)与最现代的场景(第 2 组)进行比较时,开始出现一些有趣的差异。二战后/朝鲜战争时期的演讲主要强调“国家”和相关术语,反映出对刚从大萧条伤痕中复苏的经济的关注。

在现代时代的另一端,基调明显不同。与时间相关的多个术语很明显,例如“年/年”和“时间”。早期使用“国家”与多种形式的明确“美国”形成鲜明对比。

George W. Bush 演讲的潜在异常集群 6 受到频繁使用“掌声”一词的严重影响。除去掌声,其他分歧立即出现。在广泛使用“国家”一词的情况下,这 6 次演讲使用其他术语的频率要高得多,例如“美国”和“国家”。此外,其他术语出现频率更高,如“自由”和“安全”。
国情咨文似乎在很大程度上反映了它发表的时间。尽管风格差异在单个总统以及政党和时代的组合中是可以检测到的,但差异的大小是次要的。民主党人吉米·卡特 1978 年的国情咨文与共和党人罗纳德·里根 1981 年的演讲相比与民主党同僚比尔·克林顿 1993 年的演讲有更多共同点。异常者是乔治·W·布什 (George W. Bush),他的言辞似乎与同时代的人不同。他与众不同吗?或者他的八年只是一个完全不同的时代?