异常教程
异常教程
选择分类模型
💡一则或许对你有用的小广告
欢迎加入小哈的星球 ,你将获得:专属的项目实战(已更新的所有项目都能学习) / 1v1 提问 / Java 学习路线 / 学习打卡 / 每月赠书 / 社群讨论
- 新开坑项目:《Spring AI 项目实战》 正在持续爆肝中,基于 Spring AI + Spring Boot 3.x + JDK 21..., 点击查看 ;
- 《从零手撸:仿小红书(微服务架构)》 已完结,基于
Spring Cloud Alibaba + Spring Boot 3.x + JDK 17...,点击查看项目介绍 ;演示链接: http://116.62.199.48:7070 ;- 《从零手撸:前后端分离博客项目(全栈开发)》 2 期已完结,演示链接: http://116.62.199.48/ ;
截止目前, 星球 内专栏累计输出 100w+ 字,讲解图 4013+ 张,还在持续爆肝中.. 后续还会上新更多项目,目标是将 Java 领域典型的项目都整一波,如秒杀系统, 在线商城, IM 即时通讯,权限管理,Spring Cloud Alibaba 微服务等等,已有 3700+ 小伙伴加入学习 ,欢迎点击围观
为了说明选择分类模型的问题,考虑一些模拟数据,
> n = 500
> set.seed(1)
> X = rnorm(n)
> ma = 10-(X+1.5)^2*2
> mb = -10+(X-1.5)^2*2
> M = cbind(ma,mb)
> set.seed(1)
> Z = sample(1:2,size=n,replace=TRUE)
> Y = ma*(Z==1)+mb*(Z==2)+rnorm(n)*5
> df = data.frame(Z=as.factor(Z),X,Y)
第一种策略是将数据集分成两部分, 训练 数据集和 测试 数据集。
> n = 500
> set.seed(1)
> X = rnorm(n)
> ma = 10-(X+1.5)^2*2
> mb = -10+(X-1.5)^2*2
> M = cbind(ma,mb)
> set.seed(1)
> Z = sample(1:2,size=n,replace=TRUE)
> Y = ma*(Z==1)+mb*(Z==2)+rnorm(n)*5
> df = data.frame(Z=as.factor(Z),X,Y)
Holdout 方法:训练和测试数据集
这两个数据集可以在下面可视化,上面是训练数据集,下面是测试数据集
> n = 500
> set.seed(1)
> X = rnorm(n)
> ma = 10-(X+1.5)^2*2
> mb = -10+(X-1.5)^2*2
> M = cbind(ma,mb)
> set.seed(1)
> Z = sample(1:2,size=n,replace=TRUE)
> Y = ma*(Z==1)+mb*(Z==2)+rnorm(n)*5
> df = data.frame(Z=as.factor(Z),X,Y)

我们可以考虑一个简单的 分类树。
> n = 500
> set.seed(1)
> X = rnorm(n)
> ma = 10-(X+1.5)^2*2
> mb = -10+(X-1.5)^2*2
> M = cbind(ma,mb)
> set.seed(1)
> Z = sample(1:2,size=n,replace=TRUE)
> Y = ma*(Z==1)+mb*(Z==2)+rnorm(n)*5
> df = data.frame(Z=as.factor(Z),X,Y)
要将其可视化,请使用
> n = 500
> set.seed(1)
> X = rnorm(n)
> ma = 10-(X+1.5)^2*2
> mb = -10+(X-1.5)^2*2
> M = cbind(ma,mb)
> set.seed(1)
> Z = sample(1:2,size=n,replace=TRUE)
> Y = ma*(Z==1)+mb*(Z==2)+rnorm(n)*5
> df = data.frame(Z=as.factor(Z),X,Y)
和
> n = 500
> set.seed(1)
> X = rnorm(n)
> ma = 10-(X+1.5)^2*2
> mb = -10+(X-1.5)^2*2
> M = cbind(ma,mb)
> set.seed(1)
> Z = sample(1:2,size=n,replace=TRUE)
> Y = ma*(Z==1)+mb*(Z==2)+rnorm(n)*5
> df = data.frame(Z=as.factor(Z),X,Y)
我们在训练数据集上进行预测,然后在测试数据集上进行预测。最后在底部,测试数据集(黑色曲线)和训练数据集(灰色曲线)的 ROC 曲线
> n = 500
> set.seed(1)
> X = rnorm(n)
> ma = 10-(X+1.5)^2*2
> mb = -10+(X-1.5)^2*2
> M = cbind(ma,mb)
> set.seed(1)
> Z = sample(1:2,size=n,replace=TRUE)
> Y = ma*(Z==1)+mb*(Z==2)+rnorm(n)*5
> df = data.frame(Z=as.factor(Z),X,Y)
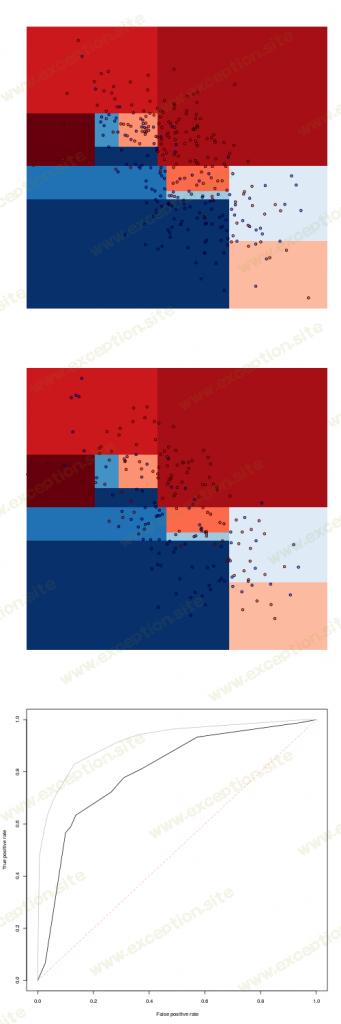
从那棵树中,很自然地可以使用 随机森林 进行预测
> n = 500
> set.seed(1)
> X = rnorm(n)
> ma = 10-(X+1.5)^2*2
> mb = -10+(X-1.5)^2*2
> M = cbind(ma,mb)
> set.seed(1)
> Z = sample(1:2,size=n,replace=TRUE)
> Y = ma*(Z==1)+mb*(Z==2)+rnorm(n)*5
> df = data.frame(Z=as.factor(Z),X,Y)
要获得预测,请在此处使用
> n = 500
> set.seed(1)
> X = rnorm(n)
> ma = 10-(X+1.5)^2*2
> mb = -10+(X-1.5)^2*2
> M = cbind(ma,mb)
> set.seed(1)
> Z = sample(1:2,size=n,replace=TRUE)
> Y = ma*(Z==1)+mb*(Z==2)+rnorm(n)*5
> df = data.frame(Z=as.factor(Z),X,Y)
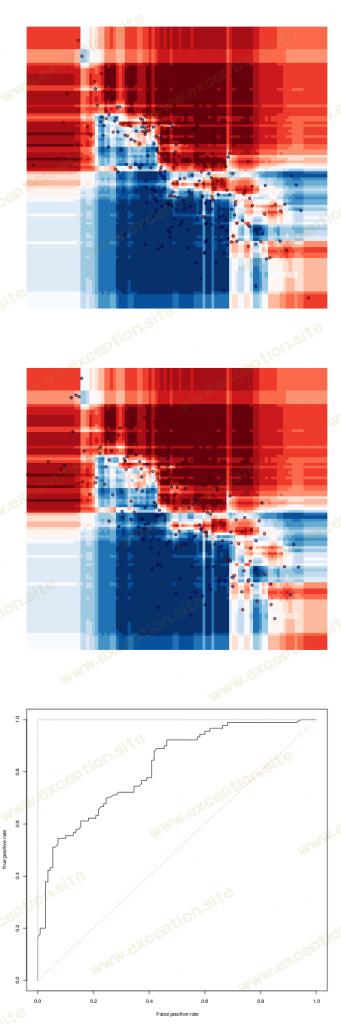
并不是说训练样本的拟合度是完美的。另一个流行的模型可能是 逻辑回归
> n = 500
> set.seed(1)
> X = rnorm(n)
> ma = 10-(X+1.5)^2*2
> mb = -10+(X-1.5)^2*2
> M = cbind(ma,mb)
> set.seed(1)
> Z = sample(1:2,size=n,replace=TRUE)
> Y = ma*(Z==1)+mb*(Z==2)+rnorm(n)*5
> df = data.frame(Z=as.factor(Z),X,Y)

后者非常接近于 线性判别分析
> n = 500
> set.seed(1)
> X = rnorm(n)
> ma = 10-(X+1.5)^2*2
> mb = -10+(X-1.5)^2*2
> M = cbind(ma,mb)
> set.seed(1)
> Z = sample(1:2,size=n,replace=TRUE)
> Y = ma*(Z==1)+mb*(Z==2)+rnorm(n)*5
> df = data.frame(Z=as.factor(Z),X,Y)

或 二次判别分析
> n = 500
> set.seed(1)
> X = rnorm(n)
> ma = 10-(X+1.5)^2*2
> mb = -10+(X-1.5)^2*2
> M = cbind(ma,mb)
> set.seed(1)
> Z = sample(1:2,size=n,replace=TRUE)
> Y = ma*(Z==1)+mb*(Z==2)+rnorm(n)*5
> df = data.frame(Z=as.factor(Z),X,Y)

要尝试非常不同的模型,请考虑
k
最近邻
(这里有 9 个邻居)
> n = 500
> set.seed(1)
> X = rnorm(n)
> ma = 10-(X+1.5)^2*2
> mb = -10+(X-1.5)^2*2
> M = cbind(ma,mb)
> set.seed(1)
> Z = sample(1:2,size=n,replace=TRUE)
> Y = ma*(Z==1)+mb*(Z==2)+rnorm(n)*5
> df = data.frame(Z=as.factor(Z),X,Y)

双变量样条的一些逻辑回归
> n = 500
> set.seed(1)
> X = rnorm(n)
> ma = 10-(X+1.5)^2*2
> mb = -10+(X-1.5)^2*2
> M = cbind(ma,mb)
> set.seed(1)
> Z = sample(1:2,size=n,replace=TRUE)
> Y = ma*(Z==1)+mb*(Z==2)+rnorm(n)*5
> df = data.frame(Z=as.factor(Z),X,Y)

或者一些 梯度提升算法
> n = 500
> set.seed(1)
> X = rnorm(n)
> ma = 10-(X+1.5)^2*2
> mb = -10+(X-1.5)^2*2
> M = cbind(ma,mb)
> set.seed(1)
> Z = sample(1:2,size=n,replace=TRUE)
> Y = ma*(Z==1)+mb*(Z==2)+rnorm(n)*5
> df = data.frame(Z=as.factor(Z),X,Y)
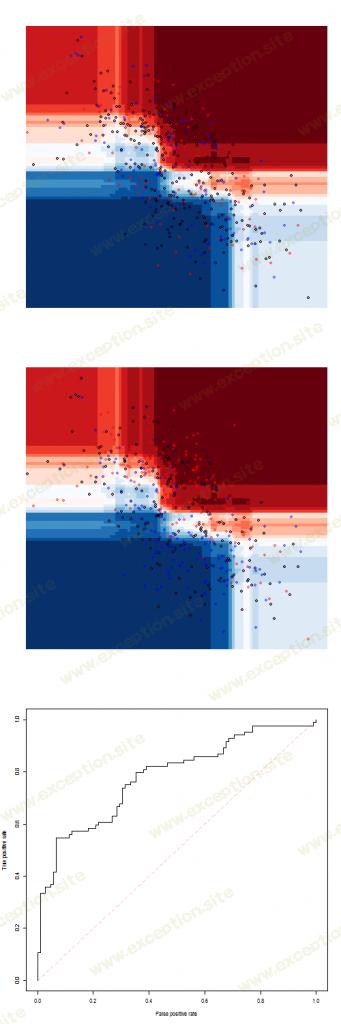
然而,使用这种 holdout 方法创建一些训练和测试数据集可能很困难。只有当我们有很多观察时才能做到这一点。即便如此,我们在创建测试样本时仍然可能不走运(仅仅是因为运气不好)。另一种方法是使用交叉验证。
使用交叉验证
这里,我们考虑one-leave-out交叉验证(但也可以考虑 v -fold交叉验证,以更快地得到结果)。
考虑这里的 分类树 。例如,要导出交叉验证 ROC 曲线,请使用
> n = 500
> set.seed(1)
> X = rnorm(n)
> ma = 10-(X+1.5)^2*2
> mb = -10+(X-1.5)^2*2
> M = cbind(ma,mb)
> set.seed(1)
> Z = sample(1:2,size=n,replace=TRUE)
> Y = ma*(Z==1)+mb*(Z==2)+rnorm(n)*5
> df = data.frame(Z=as.factor(Z),X,Y)
在这里,我存储了 n 个 模型,每次都会删除一个观察值,然后我得到对删除的观察值的预测。我们可以生成 ROC 曲线
> n = 500
> set.seed(1)
> X = rnorm(n)
> ma = 10-(X+1.5)^2*2
> mb = -10+(X-1.5)^2*2
> M = cbind(ma,mb)
> set.seed(1)
> Z = sample(1:2,size=n,replace=TRUE)
> Y = ma*(Z==1)+mb*(Z==2)+rnorm(n)*5
> df = data.frame(Z=as.factor(Z),X,Y)
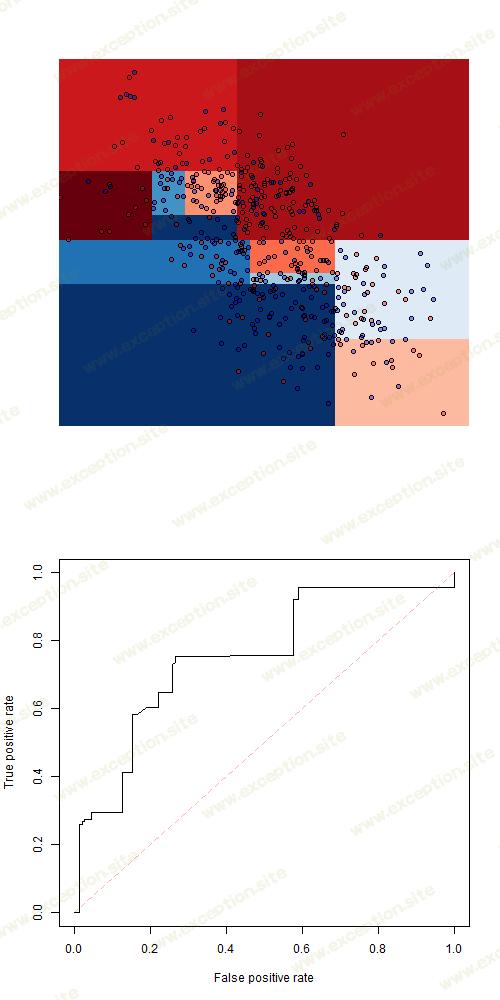
当然,一个人可以轻松获得运行速度更快的代码,但那个代码是在那个小数据集上工作的。
如果我们考虑 随机森林 ,我们得到
> n = 500
> set.seed(1)
> X = rnorm(n)
> ma = 10-(X+1.5)^2*2
> mb = -10+(X-1.5)^2*2
> M = cbind(ma,mb)
> set.seed(1)
> Z = sample(1:2,size=n,replace=TRUE)
> Y = ma*(Z==1)+mb*(Z==2)+rnorm(n)*5
> df = data.frame(Z=as.factor(Z),X,Y)
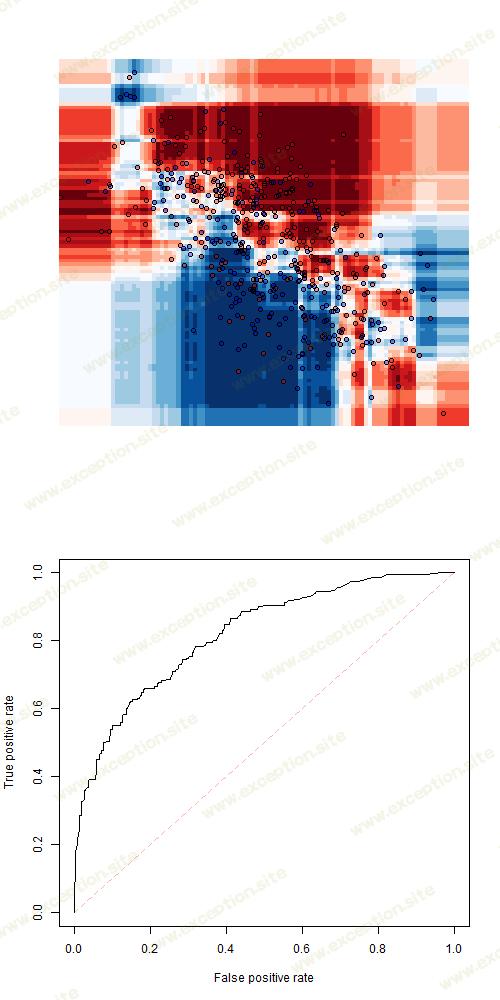
可以考虑 逻辑回归
> n = 500
> set.seed(1)
> X = rnorm(n)
> ma = 10-(X+1.5)^2*2
> mb = -10+(X-1.5)^2*2
> M = cbind(ma,mb)
> set.seed(1)
> Z = sample(1:2,size=n,replace=TRUE)
> Y = ma*(Z==1)+mb*(Z==2)+rnorm(n)*5
> df = data.frame(Z=as.factor(Z),X,Y)
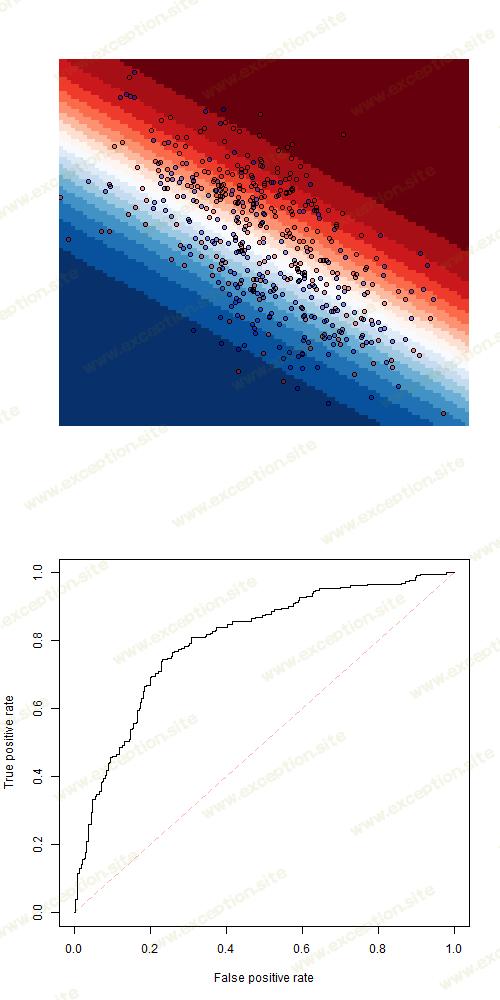
或 线性判别分析
> n = 500
> set.seed(1)
> X = rnorm(n)
> ma = 10-(X+1.5)^2*2
> mb = -10+(X-1.5)^2*2
> M = cbind(ma,mb)
> set.seed(1)
> Z = sample(1:2,size=n,replace=TRUE)
> Y = ma*(Z==1)+mb*(Z==2)+rnorm(n)*5
> df = data.frame(Z=as.factor(Z),X,Y)

而 二次判别分析 产生
> n = 500
> set.seed(1)
> X = rnorm(n)
> ma = 10-(X+1.5)^2*2
> mb = -10+(X-1.5)^2*2
> M = cbind(ma,mb)
> set.seed(1)
> Z = sample(1:2,size=n,replace=TRUE)
> Y = ma*(Z==1)+mb*(Z==2)+rnorm(n)*5
> df = data.frame(Z=as.factor(Z),X,Y)

同样,如果我们考虑另一种类型的模型,例如 k 最近邻 ( k = 5),我们得到
> n = 500
> set.seed(1)
> X = rnorm(n)
> ma = 10-(X+1.5)^2*2
> mb = -10+(X-1.5)^2*2
> M = cbind(ma,mb)
> set.seed(1)
> Z = sample(1:2,size=n,replace=TRUE)
> Y = ma*(Z==1)+mb*(Z==2)+rnorm(n)*5
> df = data.frame(Z=as.factor(Z),X,Y)

或 k 最近邻 k = 9
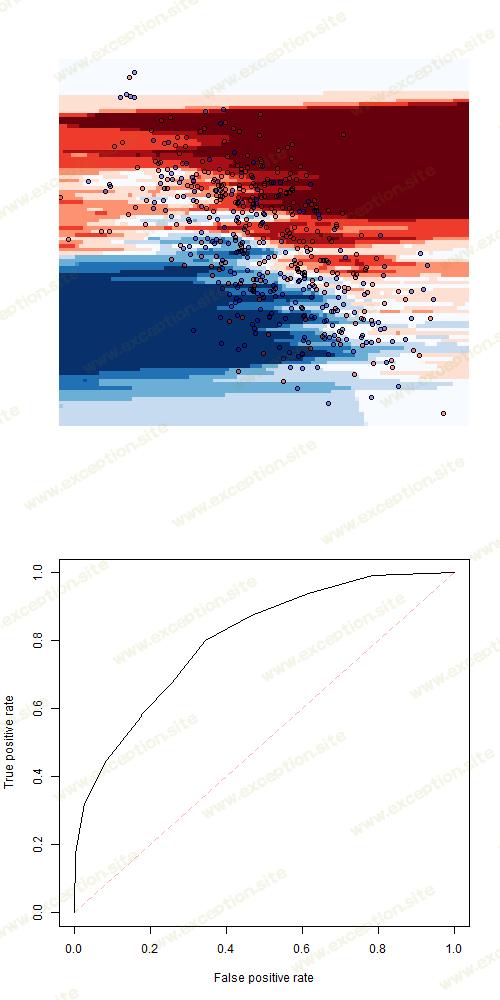
或 k = 21
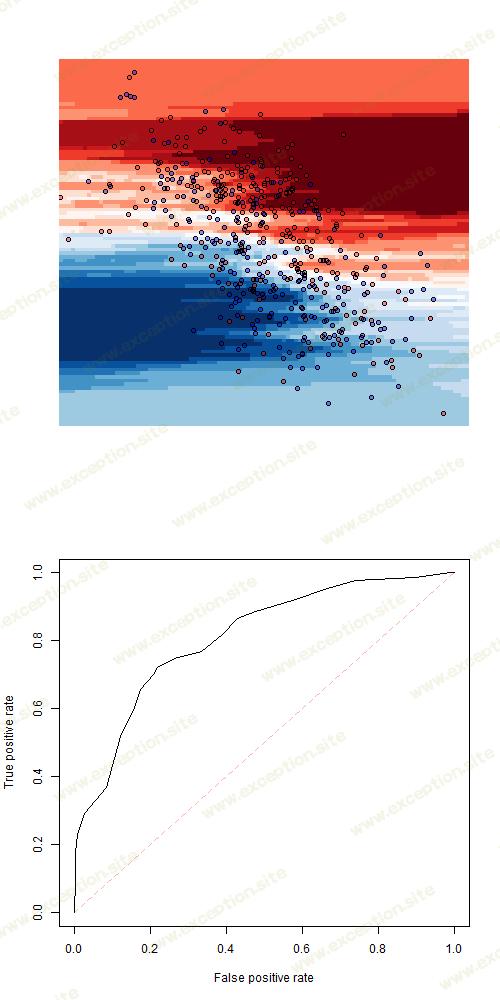
还可以考虑 使用二元样条的逻辑回归
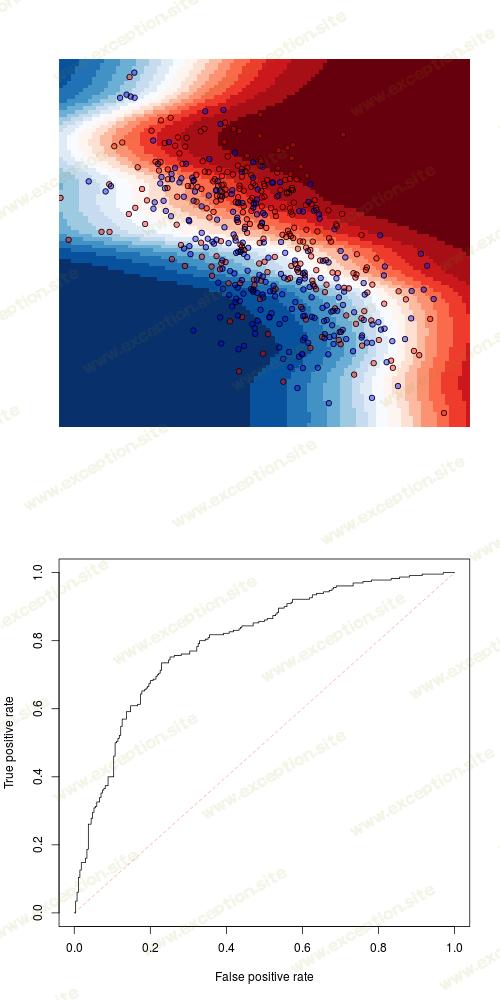
或者,最后但同样重要的是,一些 梯度提升模型 。在那一个上,我们可能无法存储梯度提升函数的 500 个输出(输出很大)。更快的代码可能是
> n = 500
> set.seed(1)
> X = rnorm(n)
> ma = 10-(X+1.5)^2*2
> mb = -10+(X-1.5)^2*2
> M = cbind(ma,mb)
> set.seed(1)
> Z = sample(1:2,size=n,replace=TRUE)
> Y = ma*(Z==1)+mb*(Z==2)+rnorm(n)*5
> df = data.frame(Z=as.factor(Z),X,Y)

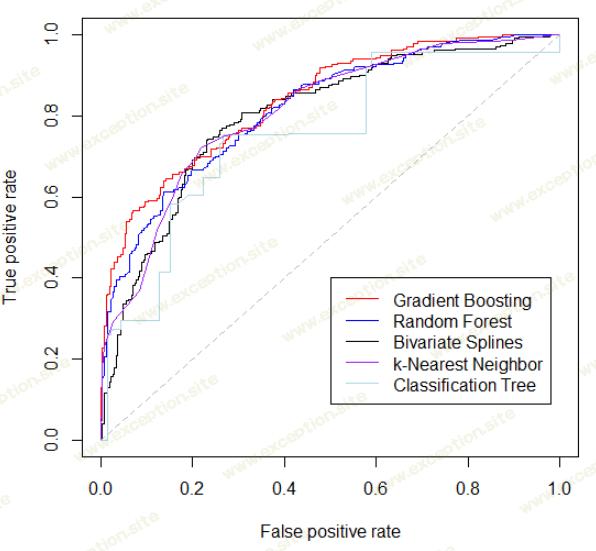
实际上,现在可以将所有这些模型与单个图表上的所有 ROC 曲线进行比较: