 异常教程
异常教程
Google Cloud Dataproc 和 17 分钟火车骑行挑战
💡一则或许对你有用的小广告
欢迎加入小哈的星球 ,你将获得:专属的项目实战 / 1v1 提问 / Java 学习路线 / 学习打卡 / 每月赠书 / 社群讨论
- 新项目:《从零手撸:仿小红书(微服务架构)》 正在持续爆肝中,基于
Spring Cloud Alibaba + Spring Boot 3.x + JDK 17...,点击查看项目介绍 ;演示链接: http://116.62.199.48:7070 ;- 《从零手撸:前后端分离博客项目(全栈开发)》 2 期已完结,演示链接: http://116.62.199.48/ ;
截止目前, 星球 内专栏累计输出 90w+ 字,讲解图 3441+ 张,还在持续爆肝中.. 后续还会上新更多项目,目标是将 Java 领域典型的项目都整一波,如秒杀系统, 在线商城, IM 即时通讯,权限管理,Spring Cloud Alibaba 微服务等等,已有 3100+ 小伙伴加入学习 ,欢迎点击围观
我上下班的火车通勤时间平均为 17 分钟。这是一件平淡无奇的事情,大多数人通过浏览移动设备、抓几个 Z 或读书来打发时间。我是那些喜欢用手机与家人和朋友联系的人之一,看看他们在欧洲的家乡都做了什么,而我却像虫子一样窝在床上。
伙计们,和我在一起。
但除了了解国内的最新事件之外,我还喜欢了解最新的科技新闻,尤其是在快速发展的云领域中发生的事情。本周,我的 AppyGeek 提要中的一条 新闻 立即从屏幕上跳了出来。谷歌在其云平台大数据套件中推出了另一种改变游戏规则的产品。
它称为 Cloud Dataproc 。
设置挑战
谷歌对这个全新的 spanking beta 工具的派对路线很简单:只需简单点击几下,Dataproc 就会启动并把 Hadoop (2.7.1) 和 Spark (1.5) 集群放在一个银盘上,可以立即使用使用和完全管理。哦,是的,我忘了——全部在大约 90 秒内完成。这听起来很有趣。

这听起来确实是一个非常大胆的主张,我认为测试它会很酷,并确保它不仅仅是那些 好得令人难以置信的营销炒作 之一。我的意思是,说真的,谁没有 90 秒的空闲时间来在云中启动一个开箱即用的 Hadoop 和 Spark 集群?!
因此,我决定在一天晚上下班回家的路上,挑战一下谷歌的虚张声势。在我的火车回到家之前,通过仅使用一台笔记本电脑并绑定我的手机,我真的可以在云中创建一个安装了 Hadoop 和 Spark 并准备好运行的 Dataproc 集群吗?
游戏开始
然而,启动集群似乎太容易了。如果谷歌的说法是正确的并且可以在 90 秒内完成,那么我在回家的路上还有超过 15 分钟的时间可以消磨。
我不太热衷于再次滚动浏览我的 Facebook 动态,看到另一个朋友在某处美丽的海滩上喝鸡尾酒享受他们的假期。所以,为了让它更具挑战性和更有趣,我放下了挑战:
-
 搭乘回程列车
搭乘回程列车
- 启动笔记本电脑和系绳电话
- 在 90 秒内创建 Dataproc 集群
- SSH 进入 master 并检查 Hadoop 和 Spark 安装
- 运行提供的 2 个示例 (Spark & PySpark)
- 删除集群
- 下船并在当地酒吧享用品脱
我为我编造的这个测试的科学性感到非常自豪。
免责声明 1: 我也有正当理由试用 Dataproc。实际上,我们在 Google Cloud Platform 上为我们的客户做了很多工作,特别是使用 BigQuery 和 Dataflow 为他们构建大数据解决方案。 Dataproc 听起来很有趣,我认为它可能对我们非常有用。
免责声明 2: 出现的一些屏幕截图可能难以阅读,尤其是从控制台截取的屏幕截图。我在挑战时没有考虑到这一点,并且在开始我的史诗之旅之前忘记放大我的浏览器。然而,一个快速提示——如果难以阅读,您可以单击图像,它会在另一个选项卡中打开原始尺寸的图像。
我们开始这个派对吧。
搭乘回国列车

我按照通常的(大概)时间下班,前往墨尔本中央商务区的 弗林德斯街车站 。我的火车是桑德灵厄姆线,原定于下午 5:23 发车。然而,我很早就犯了一个小学生错误。我完全忘记了车站楼下的网络覆盖非常非常不稳定。我担心火车一开走,我就很难在手机上找到互联网至少一两分钟,直到它开出空旷的地方。
呸!
启动笔记本电脑和 Tether 电话
由于担心网络问题困扰着我的超级科学挑战,我的火车于下午 5 点 23 分准时出发。它原定于下午 5:40 到达我的车站。那给了我 17 分钟,或多或少。门一关上,我就翻开笔记本电脑,挂上手机。毕竟,如果没有互联网,在 云 中工作有什么好处?我通过在浏览器中访问 Google Developers Console (GDC) 来测试我是否有一些互联网流量。加载速度非常慢,但至少有一些数据在流动。
我快崩溃了。
在 90 秒内创建 Dataproc 集群
第一步是启动具有 1 个主节点和 4 个工作节点的 Dataproc 集群。事实证明这非常简单,此时我不需要过多地恢复到 Dataproc 文档。在GDC中,我直接点击: Big Data - Cloud Dataproc - Clusters - Create Cluster
Big Data -> Cloud Dataproc -> Clusters -> Create Cluster

正如您在上面看到的那样,为集群取了一个非常合适的名称,我将区域设置为
us-central1-a
只是因为我喜欢美国的那个区域,并将工作节点的数量从默认的 2 个增加到 4 个。
最后,我将其他所有内容保留为默认值,例如默认实例类型
n1-standard-4
(4 个 vCPU 和 15GB RAM),以及 500GB 的主磁盘大小等。该配置导致我的 Dataproc 集群在 16 个
YARN
核心和 48GB 上进行权衡纱线内存。
这对我来说听起来不错,所以我点击了
Create
并启动了我的 Apimac 计时器。滴答,滴答……!我等了。我上下班的第一站里士满站很快就到了。我又等了一会儿。

繁荣。耗时 64 秒。是的,你没有看错,只有 64 秒。让它浸泡一下。为了让它这么快出现,谷歌必须使用一些经过认真优化的图像。我创建的集群不是特别大(我们的一个 Dataflow 集群最多可扩展到 64 个实例),但它仍然令人印象深刻。
能够如此快速地建立基础设施完全是另一回事。在大多数情况下,会配置大型 Hadoop/Spark 集群,并且在不使用时简单地保持运行,因为首先启动它们非常痛苦且成本高昂。有了这种速度,开发人员现在可以临时启动集群,并在完成后将其关闭。太棒了
好的,它恢复了业务。那只是 GDC 报告集群正在运行并准备就绪,但我想 100% 确定它确实如此。是时候使用 SSH 了。
SSH 登录并检查 Hadoop 和 Spark 安装
我在 GDC 中单击了
VM Instances
,你瞧,我可以看到我的所有 5 个集群实例都列在那里。 master很容易识别为
m
后缀的instance,其余为
w
后缀的worker。在 GDC 中查看它们,所有 5 个实例看起来都很健康:

小抱怨
:我发现必须单击
VM Instances
才能看到集群中的所有节点有点烦人。如果在单击每个集群本身时都列出了它们,那将是一个更好的用户体验。
如果您仔细查看上面的屏幕截图,您会注意到每个实例旁边都有一个方便放置的 SSH 链接。我不必浪费任何时间在我的终端和浏览器之间切换。甜的!所以我点击了 master 旁边的
SSH
,连接就建立了——尽管速度很慢。然后我运行以下简单命令来检查 Hadoop 安装:
| 1个 |
hadoop version
|

Hadoop 安装看起来不错。接下来,我想检查 Spark 是否也已成功安装。使用我刚刚用于检查 Hadoop 安装的相同 SSH 会话,我运行以下命令来启动 Scala REPL for Spark:
| 1个 |
spark-shell
|

仅供参考:
还有一个用于 Spark 的 Python REPL。只需运行
pyspark
命令而不是
spark-shell
。
正如您从我上面的屏幕截图中看到的那样,交互式 shell 毫无问题地出现了。它还立即确认了 1.5 的 Spark 版本!无需下载和安装额外的软件包。没有要更改的配置文件。没有黑客攻击。不——它只是开箱即用。我喜欢技术做到这一点。
好的,所以当 Spark shell 启动时,我借此机会通过运行以下命令快速测试它应该返回 Spark 版本:
| 1个 |
sc.context
|

运行提供的 2 个示例(Spark 和 PySpark)
Dataproc 文档提供了一些 示例 来运行和测试您的集群。您可以通过命令行或直接在 Web UI 中运行它们。我认为尝试两种方式会很有趣:
- 通过命令行运行 PySpark 和 Spark 示例
- 在 Web UI 中运行相同的 Spark 示例
是时候获得 Spark'ing 了。
当我注意到 GDC 中有一个非常方便的新功能时,我正要切换到我的终端。它被称为 Google Cloud Shell ,它会在您的浏览器中在运行基于 Debian 的 Linux 操作系统的临时 Compute Engine 虚拟机实例上启动会话。杰出的!
首先是 PySpark 示例,它只是一个简单的 Hello World:
- 从 Cloud Storage 下载 Python 脚本
- 运行 PySpark 作业
| 1个 |
cpgs://dataproc-examples-2f10d78d114f6aaec76462e3c310f31f/src/pyspark/hello-world/hello-world.py .
|
| 1个 |
gcloud beta dataproc jobs submit pyspark --cluster dataproc-train-challenge hello-world.py
|

正如您从上面的屏幕截图中看到的那样,一切顺利。到目前为止,我认为一切都很好。
接下来,我运行了 Spark 作业。您在下面看到的
file:///
表示法表示 Hadoop LocalFileSystem 方案; Cloud Dataproc 在创建集群时在集群的主节点上安装
/usr/lib/spark/lib/spark-examples.jar
:
- 运行 Spark 作业,将集群名称作为参数传递:
Big Data -> Cloud Dataproc -> Clusters -> Create Cluster

结果 PI“大约”为 3.141756。
会很紧的。
我快速浏览到 Web UI,然后快速点击
Submit a job
。然后,我继续尽可能快地填写所有需要的详细信息,例如集群名称、主类等,以再次运行 Spark PI 示例作业:

填写所需的所有详细信息非常容易。我喜欢 Dataproc 如何在提交作业以在集群上运行时从用户那里抽象出如此多的复杂性。我点击
Submit
,作业开始执行。这次可以直接在 GDC 内部跟踪作业的进度:

我可以看到没有错误,我特别高兴。但我当时也很紧张。在这一点上,我想分享我在挑战中犯的第二个菜鸟错误;我严重低估了制作您在此处看到的所有这些精美屏幕截图之前需要多长时间。是的,当然有一个键盘快捷键,但是当您乘坐高速行驶的火车旅行时,您正试图将所有东西排成一行,让我向您保证这不是在公园里散步。我估计总的来说,做截图至少花费了我 2 分钟。
最后的工作完成了,我通过以下方式检查了我运行的所有 3 个工作的结果:
Cloud Dataproc - 职位
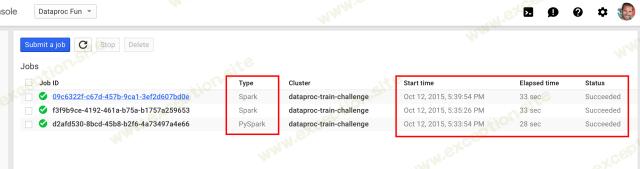
从上面可以看出,所有三个作业都报告为成功。有 2 个 Spark 作业(1 个通过命令行运行,1 个通过 Web UI 运行)和一个 PySpark 作业(通过命令行运行)。最后一项工作耗时 33 秒,并于下午 5:39:54 完成!记住——我的火车原定于下午 5:40 到达!
我看了看外面,然后我意识到我们刚刚离开了我之前的最后一站。幸运的是,火车晚点了大约 1.5 分钟。但是,它 离舒适太近 了。
删除集群
Google 提供了多种删除集群的方法,即从命令行、REST API 或从 Web UI。我只有足够的时间留给后者,所以我选择了我创建的集群 (
dataproc-train-challenge
),最后单击
Delete
:

我等了。我可以看到我停止了。我等待着。还剩大约 60 秒。它仍然显示' 删除 '。该死,我想我不会成功的。
我又等了一会儿。我可以看到我停靠的站台,火车开始减速。仍在“ 删除 ”。老鼠!我一直在等。火车停下来,车门打开,我不得不下车。还是‘ 删除 ’。
游戏结束。
下船并在当地酒吧享用品脱(和结论)
从技术上讲,我还没有完成 Dataproc 训练挑战,因为集群在我下车之前没有删除。但是我
 尽管如此,我认为这仍然是一项巨大的成就,值得一品脱。
尽管如此,我认为这仍然是一项巨大的成就,值得一品脱。
然而,当我在当地的酒吧喝着我的吉尼斯奶油时,我确实检查了 GDC,看看集群是否最终被拆除并删除了。它有过。我可能只是超过了它几秒钟。嘎!
谷歌的新 IaaS 应该是很多大数据开发人员感兴趣的东西。“ 想在 90 秒内启动一个完全托管的 Hadoop/Spark 集群吗?” 没问题的同伴。 “ 想要轻松地将作业提交到您的集群?” 好吧,别再看了。 ' 想看看大数据的未来吗? '好吧,伙计们,就在这里。
谷歌的战略一目了然。他们希望通过为我们处理所有繁重的工作和基础设施来减轻我们作为开发人员的负担。换句话说,降低进入门槛,并吸引更多开发人员进入他们的云。 Dataproc 毕竟是 IaaS。这意味着我们可以腾出时间专注于代码,并及时回答利益相关者向我们提出的问题。
这一切都是为了简单,并抽象出管理大型集群以管理海量数据集所带来的复杂性。这一点在谷歌大数据套件上的所有产品中都很明显,例如 BigQuery 、 Dataflow ,现在还有 Dataproc 。不过,并不是每个人都会喜欢这样,而是更愿意完全控制他们的环境(例如出于隐私或立法原因),并有能力进行调整和调整。但在我看来,如果可以的话,你应该采用这种新方法。
除了 Dataproc 快得离谱的速度和漂亮的简单性,我还认为这是一件很棒的事情,谷歌没有与 Hadoop 和 Spark 等开源技术竞争,而是拥抱它们并将其集成到他们的云生态系统中。这对于那些已经在 Hadoop/Spark 堆栈上进行开发的人特别有用,因为将他们现有的工作迁移到 Dataproc 应该是一件轻而易举的事。
我还想在不久的将来进一步进行测试:
- 我很想在 AWS 上使用 Elastic MapReduce (EMR) 进行同样的科学训练挑战,看看它如何与 Dataproc 相提并论。
- 启动一个更大的集群,看看需要多长时间。
- 使用随 Dataproc 部署的 连接器 启动一些处理来自 BigQuery 的数十亿行和 TB 数据的 Spark 作业,并查看集群在推送时的性能。
最后,虽然我没能完全完成 Dataproc 17 分钟火车挑战,但在好酒保给我端来下一品脱啤酒之前,我还是设法喝完了我的一品脱啤酒。干杯!