 异常教程
异常教程
如何“我被骗了?”在 Azure 上执行
💡一则或许对你有用的小广告
欢迎加入小哈的星球 ,你将获得:专属的项目实战 / 1v1 提问 / Java 学习路线 / 学习打卡 / 每月赠书 / 社群讨论
- 新项目:《从零手撸:仿小红书(微服务架构)》 正在持续爆肝中,基于
Spring Cloud Alibaba + Spring Boot 3.x + JDK 17...,点击查看项目介绍 ;演示链接: http://116.62.199.48:7070 ;- 《从零手撸:前后端分离博客项目(全栈开发)》 2 期已完结,演示链接: http://116.62.199.48/ ;
截止目前, 星球 内专栏累计输出 90w+ 字,讲解图 3441+ 张,还在持续爆肝中.. 后续还会上新更多项目,目标是将 Java 领域典型的项目都整一波,如秒杀系统, 在线商城, IM 即时通讯,权限管理,Spring Cloud Alibaba 微服务等等,已有 3100+ 小伙伴加入学习 ,欢迎点击围观
我一直非常公开地写关于 Have I been pwned (HIBP) 是如何构思、构建以及它是如何执行的。如果有时间回顾那场比赛,那就是在 Ashley Madison 突破后的前几天。我想分享我在随后三天的极度混乱中所观察到的“缺点和所有描述”。
我第一次得知这件事是在当地时间星期三早上 6 点左右,那是在洪流首次播出后不久(记住,我在澳大利亚,这对你们大多数人来说都是未来)。白天,我拆除了漏洞,对其进行了处理,并最终在当晚 20:30 左右获得了数据,之后流量迅速增加,直到第二天早上 11:00 达到峰值。这是来自 Google Analytics 的 19 日星期三、20 日星期四和 21 日星期五的三天图表(星期六也异常繁忙,但所有 New Relic 图表都是三天,所以我将坚持该时间范围):

想一想:网站从最安静时的每小时 96 个会话增加到最繁忙时的 55,611 个。当我们谈论云规模时,这就是它的化身—— 我看到流量在 24 小时多一点的时间里增加了 58,000%。 这是一个“标题”数字,但这里有另一个数字,这是同一三天内的性能图表:
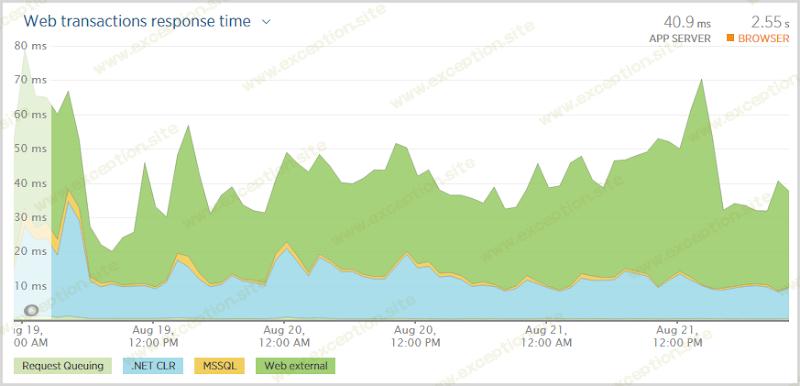
我喜欢这张图的原因是它与流量的这种变化毫无关联!事实上,在流量几乎不存在的早期,交易时间可能会稍长一些。我对 Azure 的扩展性足够好,无论网站上有十几个人,还是这么多人,性能都不会降低:
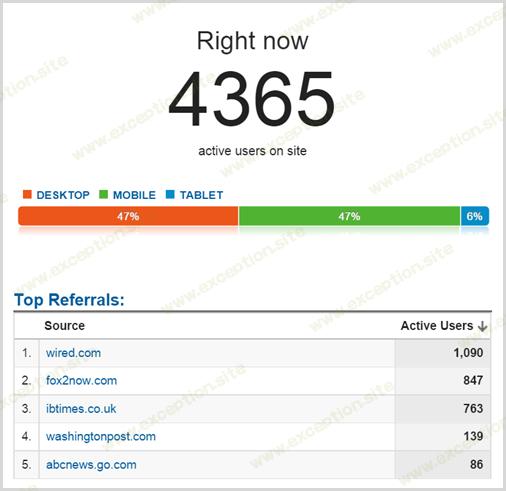
我在星期四早上 05:46 从 Google Analytics(分析)中截取了该数据,当时有 34,240 个会话,按比例计算,55,611 个会话的高峰时段更像是同时进行了 7k。实际上,它更像是 一个小时内 平均 8.5k 个并发会话, 因为这是根据 Google Analytics 得出的,我发现由于广告拦截器和其他阻止跟踪的工具, 实际 流量通常高出 20% 左右。那一小时内的实际峰值?谁知道,可能超过 10k。
现在我说这将是一个“缺点和所有”的分析,这意味着我需要向你展示这个:

当我最初推送将 Ashley Madison 数据从公共搜索结果中排除的代码时(更多信息请点击 此处 ——这是一篇非常重要的帖子,讲述了我如何做出判断决定该数据 不应 被公开搜索),我得到了一个空引用当有人订阅该服务、验证了他们的电子邮件并且 不在 Ashley Madison 漏洞中时例外。他们仍然成功订阅,没有人 错过 被告知他们在那里的信息,但那些没有被告知的人却犯了错误。我让 Raygun 对我发疯了,所以我修复了它并快速推送它,但这意味着 0.7% 的请求在数据点涵盖的小时内有错误。这是最繁忙时期的错误率更具代表性的图表:
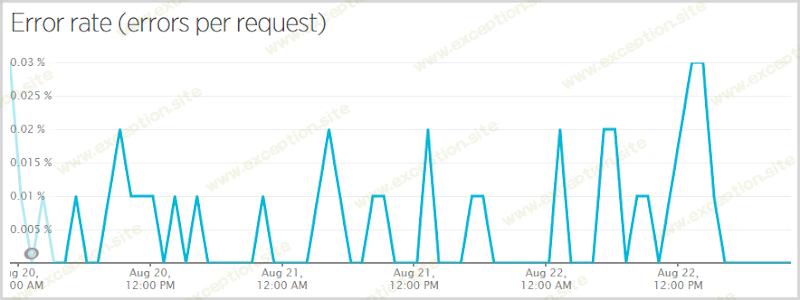
这仍然是一个为期三天的时间段,但它跳过了星期三,只执行了星期四、星期五和星期六。计算结果的错误率为 0.0052%(出于某种原因,New Relic 只在首页较小的图表上给出了这个数字),换句话说,99.9948% 的请求成功了。那么失败的有哪些呢?开始了:
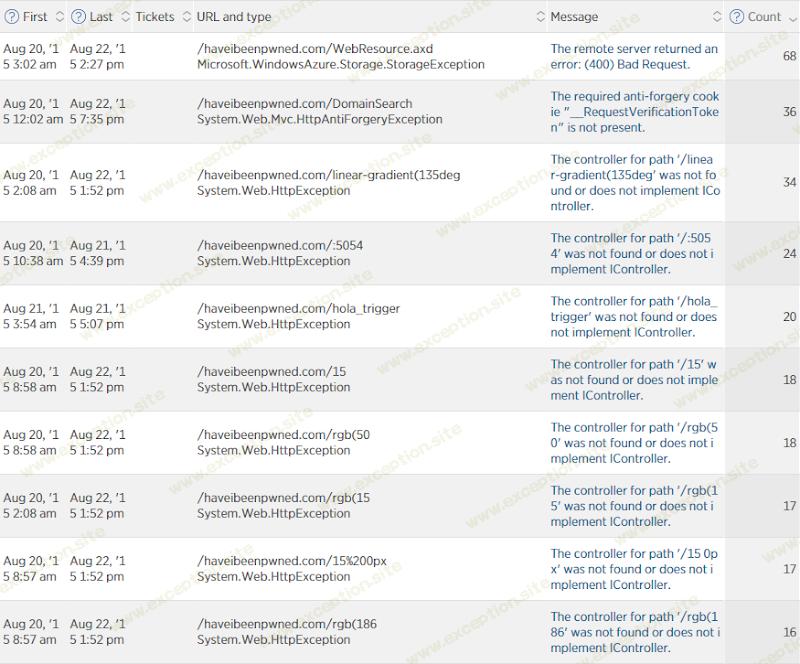
这些主要不是面向用户的错误。 WebResource.axd 用于使用 NWebsec 自动记录内容安全策略违规(顺便说一下, 我的 Pluralsight 课程 在所有混乱中上线!)并且当非常大的违规不适合表存储时,有时会失败(出于某种原因,我有时会在其中看到大数据 URI)。当人们(或机器人)试图进行域搜索而不传递防伪令牌(安全扫描工具的最爱)和一堆完全不相关的错误(例如格式错误的请求到非-现有资源由于各种原因完全超出了我的控制范围。事实上,如果将这些从错误百分比中剔除,实际面向用户的错误接近于 0%,几乎是完美的——每 100,000 个请求中不到一个实际错误。 非常 偶然的表存储超时或无法联系 SQL Azure。请注意,这与负载无关 - 有时我会在网站上只有少数人看到这种性质的错误。当然,我很想把它记下来,但我很高兴!
当严重的容量受到冲击时,我最感兴趣的事情之一就是 负载 的去向。我知道 流量 在哪里——它在首页和搜索帐户——但在哪里进行了艰苦的工作?我发现性能受到影响的最大区域是人们注册接收通知时:
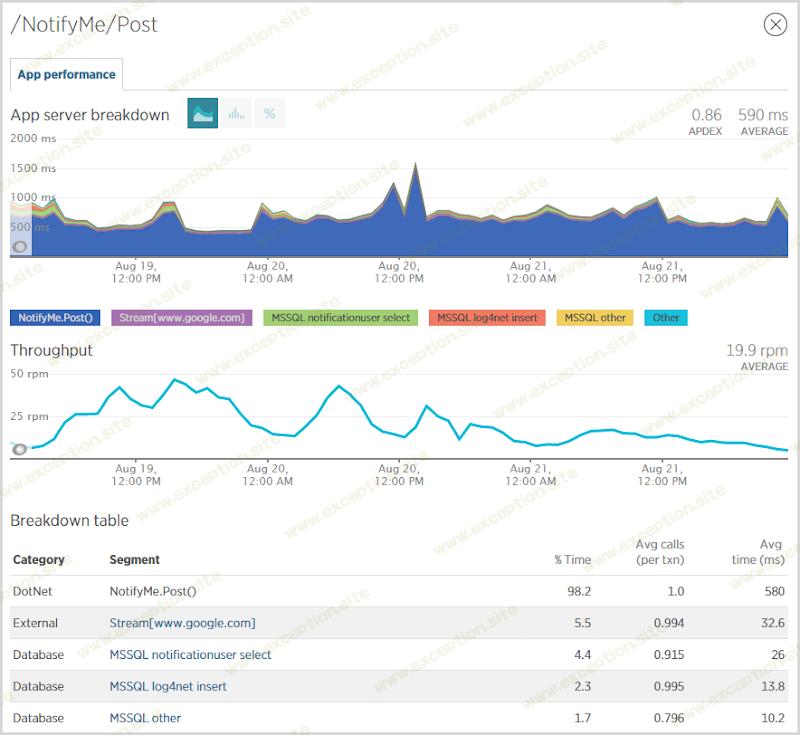
在此期间,我有大约 9 万人注册了通知,正如您从上面的图表中看到的那样,它很慢。问题出现在 NotifyMe.Post() 事件中,平均耗时 580 毫秒。此事件直接连接到 Mandrill 的 SMTP 服务器以发送效率极低的验证邮件。我真正应该做的是将它放入消息队列,立即向用户发送响应,然后让 WebJob 作为后台进程在几秒钟后发送电子邮件。这将阻止邮件传递阻止响应,因此用户可能会恢复大约半秒的生命。另一方面,如果我使用 WebJob 实际发送邮件,那么它仍然在 Web 服务器上执行,所以虽然我希望能够通过这样做来对系统的可扩展性进行改进,但我' m 只是在同一基础设施上运行的不同进程之间洗牌相同的负载。当然,通过与 Azure 中的存储而不是与完全不同的地方的邮件服务器进行通信有弹性的好处,但除非我将 WebJob 分发到其他基础设施,否则我不会真正取回任何 CPU 周期。
在系统的后端,这是我在数据库中看到的:
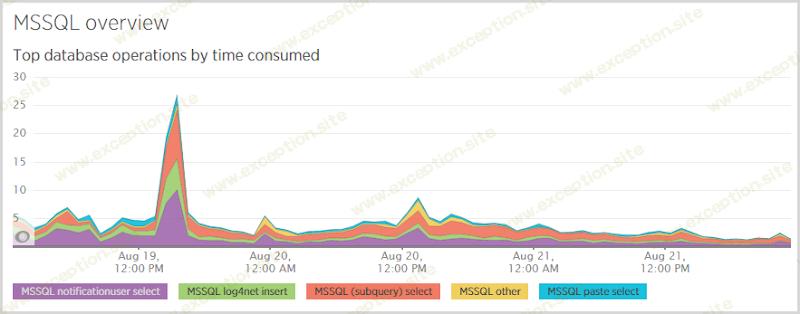
这里最突出的是“通知用户选择”;当有人订阅通知时,我首先检查他们是否在数据库中,这样我就知道是向他们发送一封“嘿,你已经订阅了”的电子邮件还是一封“这是你的验证令牌”的电子邮件。在他们点击验证链接后,我还需要从该表中进行选择,该验证链接通过令牌拉回他们的记录。这些选择很昂贵,您会在数据库响应时间中再次看到它:
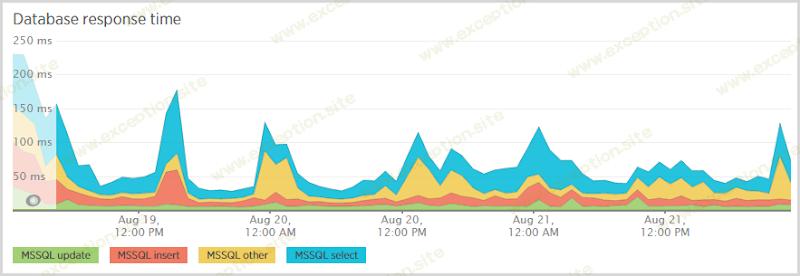
在此期间,我确实多次更改了 SQL 数据库规模(稍后会详细介绍),所以我预计会有一些波动,但显然选择仍然是成本的最大份额。我需要更仔细地查看该表,看看索引发生了什么。它们适用于通过电子邮件和令牌进行查询,但对于其中包含大约 25 万行的表,运行速度应该比这快。
我得到的一个与此相关的有趣统计数据是调用者将选择查询分配给 notificationuser 表:
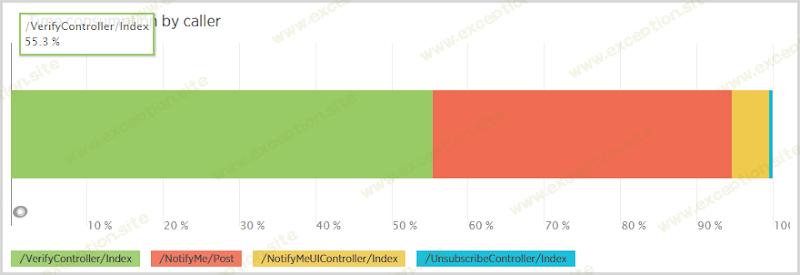
现在仔细想想这里的工作流程:有人向 NotifyMe 控制器发帖以订阅通知,然后 80% 的时间他们在收到电子邮件后返回并点击 VerifyController(我假设有 20% 的流失率要么不是收到电子邮件或注册其他地址的人)。关键是来自注册(“/NotifyMe/Post”调用者)的调用应该比验证更多,但验证消耗了 notificationuser 表中所有选择的 55%。为什么是这样?
我在一些次优代码中发现了这个问题,这些代码首先通过令牌检索用户,这样我就可以查看令牌是否有效并且是否已经过验证,然后它会这样做:
public void VerifyUser(int id)
{
var notificationUser = _db.NotificationUsers.Single(n => n.Id == id);
notificationUser.IsVerified = true;
notificationUser.VerificationDate = DateTime.UtcNow;
_db.SaveChanges();
}
这是一个非常典型的实体框架模式,但它效率低下,因为它首先使用一个查询从数据库中提取记录(因此现在在验证时进行两个选择查询)然后在使用修改后的实体进行更新之前更新 IsVerified 和 VerificationDate 属性。在这种情况下,更简单实际上会更好,我应该在 ExecuteSqlCommand 中使用更新语句来解决它。事实上,我什至不需要首先进行选择以查看令牌是否有效,我可以从更新语句中返回一个值,指示一行是否已更新(令牌存在)或不(令牌无效) ).坦率地说,大多数时候它甚至都不重要,但随着您扩展这些额外的查询,开始对基础架构造成影响。
我看到的另一个有趣的数据库模式是这个:
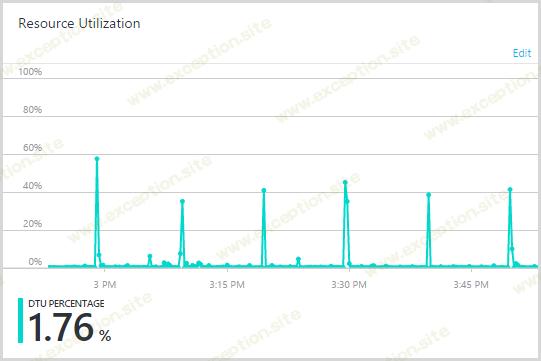
这些峰值间隔 10 分钟,因此很明显某处有一个过程在周期性的基础上导致负载。起初我想知道是否有外部玩家在某处攻击正在破坏数据库的资源,然后我想起了验证提醒服务……每 10 分钟运行一次。这是一个 WebJob,每 10 分钟进入数据库并检查是否有至少三天的待处理订阅验证。正如我之前提到的,只有大约 80% 的注册最终会验证他们的电子邮件地址,剩下的 20% 会在垃圾邮件过滤器中丢失或被意外删除或其他原因。提醒服务随后会发送一封“嘿,您已注册但从未验证过”的电子邮件。显然,提取此数据的查询现在正在激增 DTU。
我怀疑发生这种情况是因为距最初的繁重负载已经过去了大约三天,并且由于注册量的大量增加,查询从一个更大的表中提取了更多的数据。我还发现该表没有特别优化;我正在选择通知用户,查询他们是否活跃、是否经过验证、是否收到提醒以及他们是否在三天前注册。对于这个查询,我没有合适的索引 , 我是一个一个地抓取它们,当你谈论正常的卷时,这不是问题,但一旦事情变大,显然 是 一个问题。好的,它仍然是一个后台进程,因此提醒过程的持续时间不会直接阻止对用户的响应,但它仍然会激增数据库活动,这可能会对其他查询产生不利影响。
顺便说一下,我可以很好地访问所有这些信息,因为我的 Azure 门户如下所示:
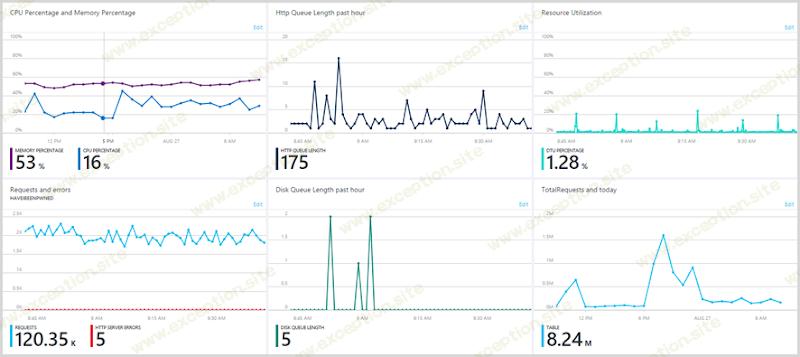
我定制了我自己的仪表板,以确保我需要的一切都在一个地方。请查看有关 Azure 门户改进的 这篇文章以获得一些相关指导,我 强烈 建议其他使用 Azure 的人也这样做。它非常强大,真的可以让您控制正在发生的事情。
当我在仪表板和信息上时,我保留了一个 Chrome 窗口,其中包含我在不同选项卡中监控生命体征所需的一切:
带有实时流量数据的 Google Analytics,带有性能统计数据的 New Relic,带有错误的 Raygun,带有云数据的 Azure 和用于电子邮件发送的 Mandrill。能够快速查看整个应用程序和基础架构中发生的事情绝对是无价的。说到基础设施……
我过去曾写过关于 如何配置 Azure 以扩展 Web 服务器基础设施的文章 ,正如您所期望的那样,在此期间我确实使用了其中的一些:
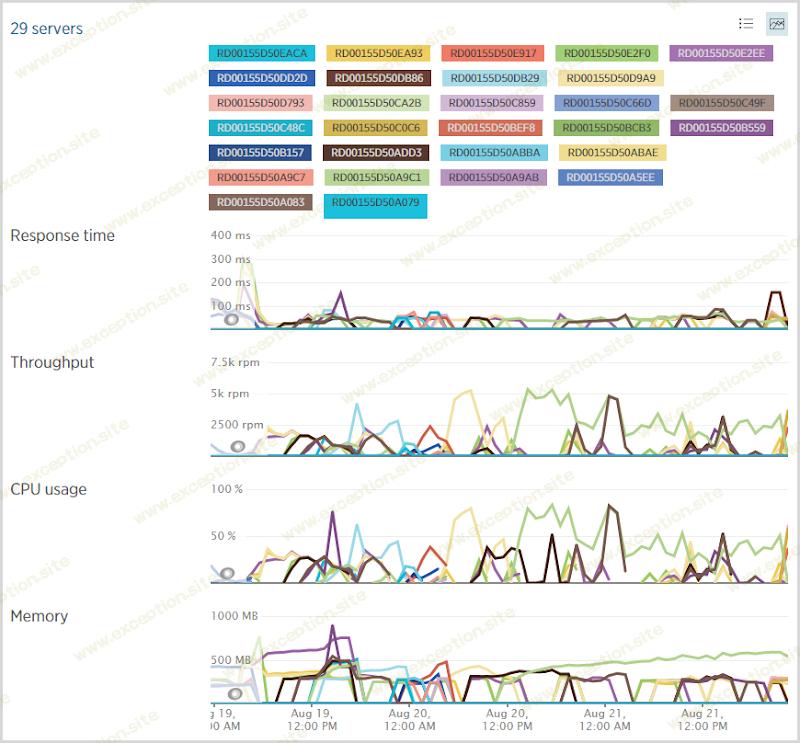
在正常情况下,我运行一个 Azure 网站的中型实例,然后根据需要扩展到多个实例。不过,在星期三晚上睡觉之前,我把它放大到一个大号,直到星期六下午才换回来。这给了我更大的增长空间(大约是中型实例的两倍),当然,当你查看一些服务器集群时,中型实例可能会变得有点紧张。也就是说,我不完全确定我的扩展阈值是完美的,因为看起来服务器数量在某些地方有点摇摆不定。例如,这是来自 Azure 门户的服务器数量:

这些高峰与交通量并不完全一致,这有几个原因。首先,交通不是交通;不同的请求模式确实会改变负载。例如,对 API 的大量点击会使系统的不同部分承受对图像或 CSS 的大量点击。另一件要记住的事情是, 我也有一堆 WebJobs 在后台运行 。他们独立于站点流量增加,并且当您看到 10 台服务器同时运行时,他们在星期四清晨加班。事实上,我 手动 扩展到 10 以进一步并行化作业,一旦我返回自动缩放,它就会稳定在 4 个左右的大实例,给予或接受。
我目前使用的自动缩放规则如下所示:
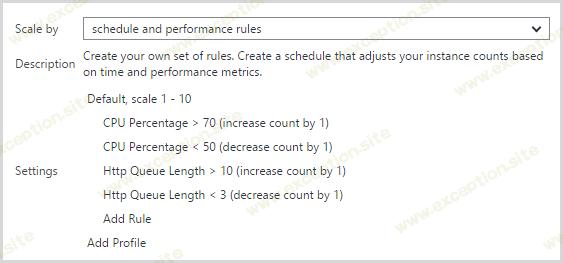
我发现像我最初那样单独在 CPU 上扩展并不够早。这一切都是在几周前完成的,因为 API 被频繁访问,我注意到一个中型实例保持稳定在 8k RPM 左右。我会手动添加另一个实例,RPM 会上升。我发现负载并未导致通过 CPU 发生横向扩展,但 HTTP 队列长度在增加,因此这成为触发扩展的指标。我现在有点怀疑,队列长度测量可能会导致横向扩展,然后 CPU 测量会 在 不久后导致扩展,从而导致溜溜球效应。我可能会降低用于减少实例数的最小 CPU 阈值来解决这个问题。
诚然,这是一个相当激进的规模概况。我总是拥有比我需要的更多的力量,上面的性能数据证明了这一点。当然,所有这一切都让人们想知道——我花了多少钱?!让我们找出答案!
以下是 Azure 计费系统的所有相关内容。我将解释每张图表,然后按市场价格绘制出成本。我将针对从 8 月 13 日到 8 月 23 日捕获这些图表的这个计费周期执行此操作,它跨越了疯狂的时期和之前的大约一周。请记住,这些日期是美国时间,所以如果是太平洋标准时间,那么实际上比我引用的其他日期晚 17 小时。它不会影响数字,但与上面的图表相比,您会发现时间有点偏差。
我使用了 424.33 小时的中型应用服务。
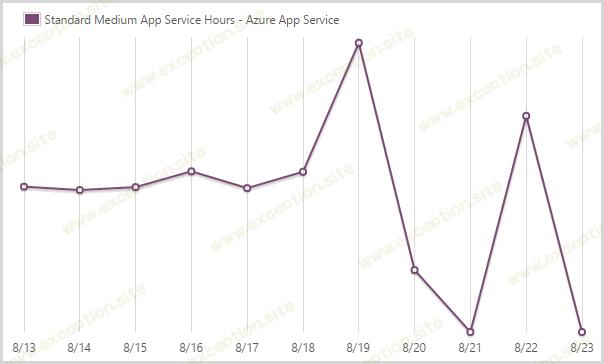
Azure 应用服务 就是您以前可能称为网站服务的内容。您可以看到在横向扩展开始发生之前它是如何非常稳定的。然后它会下降,因为我只求助于大型实例。一旦负载消失并且图表中的最后一天根本没有任何数据要注册,我就会回到中等。
我消耗了 155.64 小时的大型应用程序服务。

这个图有点像中等实例的倒数,因为它在不中等时就很大,而在不大时就中等,好吧,你明白了。我现在已经完成了 large,除非事情再次变得疯狂......
我从 1 区的应用程序服务发送了 16.13GB。
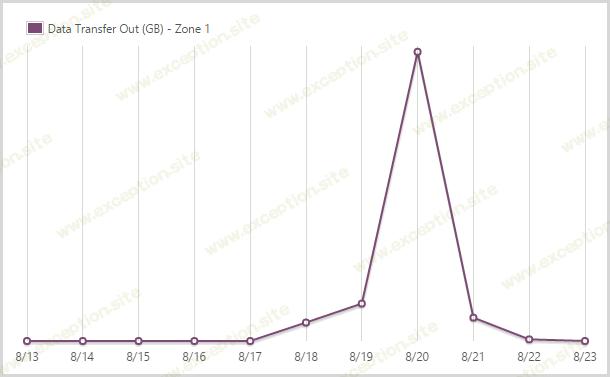
Azure 有 一个分层的出口数据收费模型 ,这实际上意味着你根据托管数据的位置支付不同的金额。 HIBP 位于美国西部的数据中心(它最接近使用它的大多数人),而且恰好也是最便宜的。您可以获得前 5GB 免费和 入口 数据(发送到站点的任何内容)是免费的。
我从 1 区的 CDN 服务发出了 122.9GB。

我使用 Azure CDN 服务 托管 pwned 站点的徽标。当 CDN 来自另一个区域时, 您需要为其支付更多费用,但它也更快,因为这显然意味着在全球范围内分发内容。我很乐意为此付出代价——我从那里的所有东西中优化了上帝,它使事情变得更快,所以恕我直言,这是值得的。
我从 2 区的 CDN 服务发出了 9.99GB。
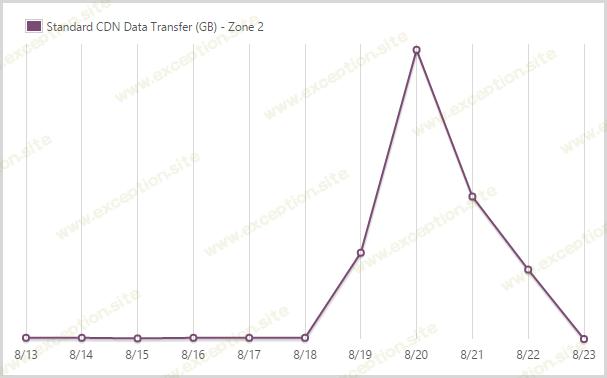
这是另一个区域——1 区的价格上涨了 59%,但显然微软在不同地点受到不同数据成本的打击,所以这很公平。这个数字要小得多,因为流量 主要 由美国观众驱动。
我在地理冗余表和队列存储中存储了 39.62GB。
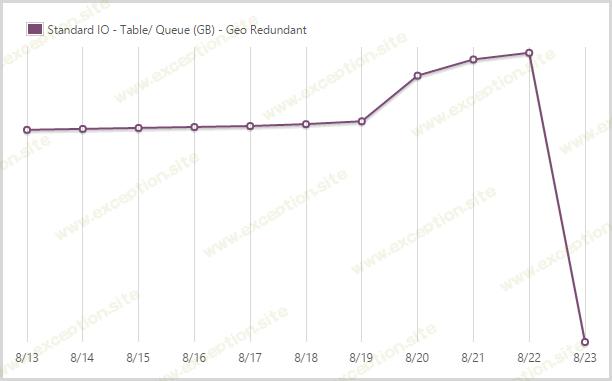
过去,我 写过很多关于我对表存储的热爱 ,它在此期间表现出色。我将人们在表存储中访问该站点时搜索到的所有数据以及我的 CSP 违规报告之类的东西存储起来。队列存储然后广泛用于其他进程,特别是与 WebJobs 结合使用。我为异地冗余存储支付了额外费用,以便在发生 哥斯拉事件 时在另一个位置拥有一份副本。
我提交了 241,702,400 笔存储交易。
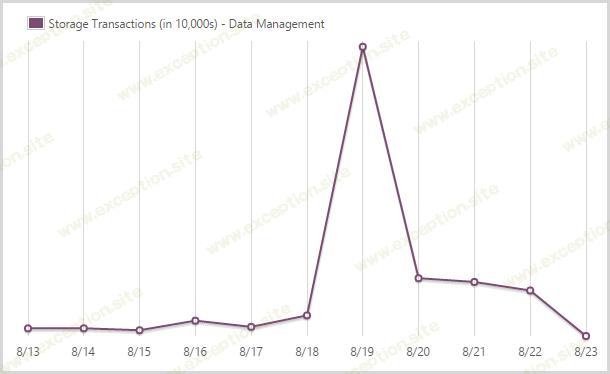
是的——将近 十亿的四分之一! 您还需要为表存储中的事务付费。当我加载 Ashley Madison 数据时,这里出现了一个巨大的峰值,因为该过程可能会导致单个记录的多次命中(即它已经存在,所以我必须将其拉出,更新它然后将其放回原处)。
我使用了 43.96 天的标准 S0 SQL 数据库。

这是 SQL 数据库服务通常运行的级别,这是您的入门级标准数据库即服务。这实际上不是一个公平的图表,因为我的帐户上还有其他 S0 数据库,而不仅仅是 HIBP 背后的数据库。这会稍微夸大数字,但不会夸大太多。请注意图表是如何快速下降的——我在加载 Ashley Madison 数据时扩大了数据库,因为在加载期间它会在一段时间内达到最大值(在数据加载期间我仍然使用 RDBMS)。
我使用了 1.92 天的标准 S1 SQL 数据库。
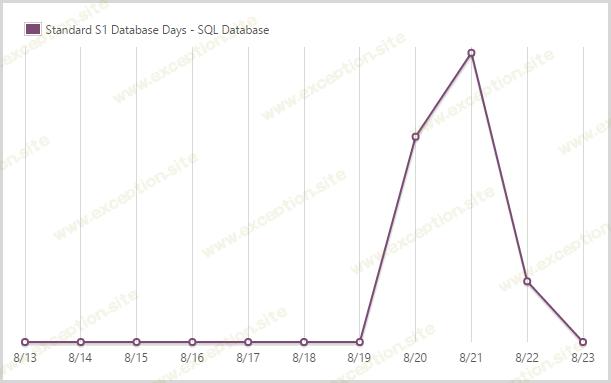
在最初的疯狂时期过后,一旦我看到 DTU 几乎保持平稳(SQL 仅在有人订阅通知时才会定期命中),我就缩减到 S1。这只是您将在下一张图中看到的 S3 DTU 的 20%,但在几乎没有负载的情况下,很明显我可以将其后退,我只是留下了一点保险,没有一路走下去回到 S0。
我使用了 1.46 天的标准 S3 SQL 数据库。
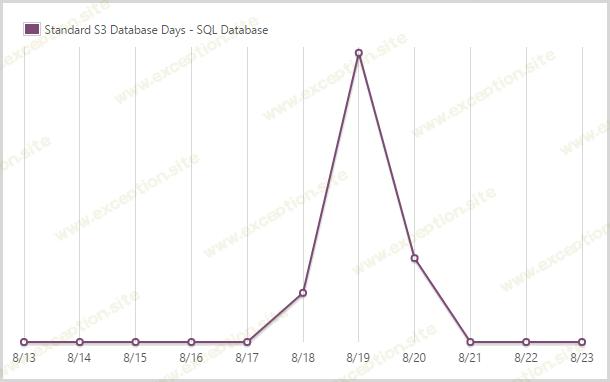
这是填补 S0 和 S1 数据库之间空白的尖峰。
那么你认为这一切让我付出了什么代价?这个练习让我损失了多少?老实说,在活动期间,一切都是“先规模化,然后再提问”,我确实有一种不舒服的感觉,我要转身看到 1000 美元或更多的成本,特别是运行可扩展到 10 台机器的大型实例。我该如何解释我长期以来坚持的 Azure 支付低于咖啡支付的立场?!
这就是——整套成本:
|
服务 |
单位 |
单位成本 |
全部的 |
|
标准中型应用服务(小时) |
424.22 |
0.15 美元 |
63.63 美元 |
|
标准大型应用服务(小时) |
155.64 |
0.30 美元 |
46.69 美元 |
|
应用服务数据传出,区域 1 (GB) |
16.13 |
0.087 美元 |
1.40 美元 |
|
CDN服务数据传出,zone 1 (GB) |
122.90 |
0.087 美元 |
10.69 美元 |
|
CDN服务数据传出,zone 2 (GB) |
9.99 |
0.138 美元 |
1.38 美元 |
|
地理冗余表和队列存储 (GB) |
39.62 |
0.095 美元 |
3.76 美元 |
|
存储事务(每 10,000 个) |
2,417.024 |
0.0036 美元 |
8.70 美元 |
|
标准 S0 SQL 数据库(天) |
43.96 |
0.4848 美元 |
21.31 美元 |
|
标准 S1 SQL 数据库(天) |
1.92 |
$2.4192 |
4.64 美元 |
|
标准 S2 SQL 数据库(天) |
1.46 |
$4.8384 |
7.06 美元 |
|
169.29 美元 |
除了阿什利·麦迪逊 (Ashley Madison) 活动并没有让我花费太多,因为这个数字包括了我通常会在 10 天内支付的所有服务,无论如何,账单都涵盖了。说实话, 为 Azure 向 150 万用户提供 300 万个页面,整个事件花费了我大约 130 美元 。实际上,因为我的目标是完全透明,Mandrill 也有一些成本用于发送相当多的电子邮件:
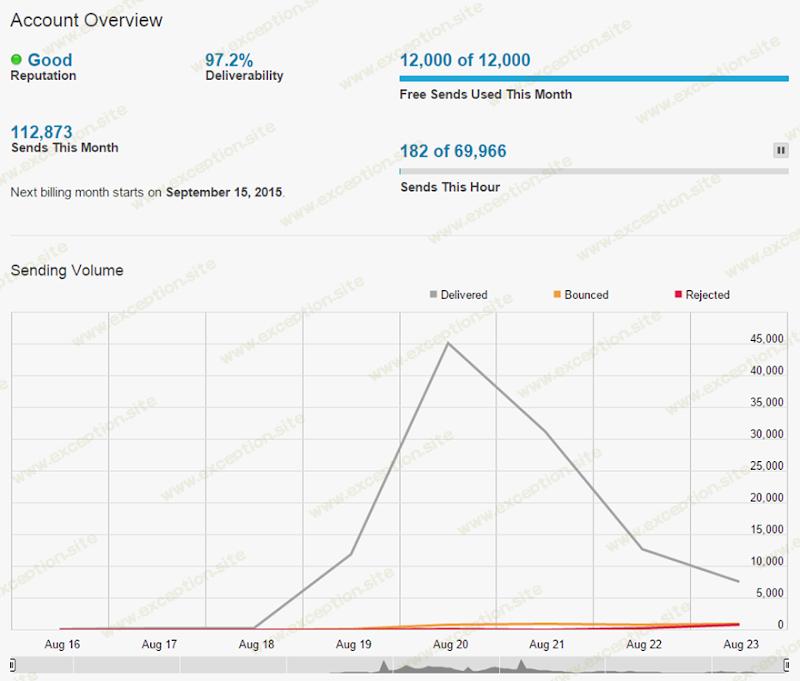
每月免费发送 12k,我通常不会进入付费领域。但是,当我这样做时,每千封电子邮件整整 20 美分,而且我的帐户每花费 5 美元就会自动充值,所以我从 Mandrill 收到了 三张账单, 总计 15 美元!所以总共大概是 145 美元。
让我再告诉你一件事:这是整周的统计数据,所以这是从 17 日星期一到 23 日星期日(含):
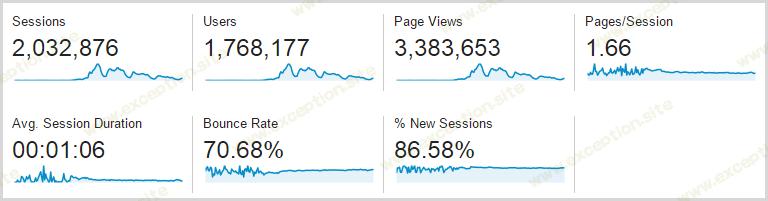
这是一个很大的数字——超过 300 万的页面浏览量——当然,细节决定成败,这又回到了第一张图表,该图表显示了从周四开始的流量有多么密集。真实情况是,这是四天的流量传播,因为相对而言,前三天几乎持平。哦 – 根据之前的评论,它是 Google Analytics,所以除此之外还有 20%,您将 在三天内查看 400 万次页面浏览量 。
但这是我真正想展示的以及我想如何结束分析:正常运行时间:
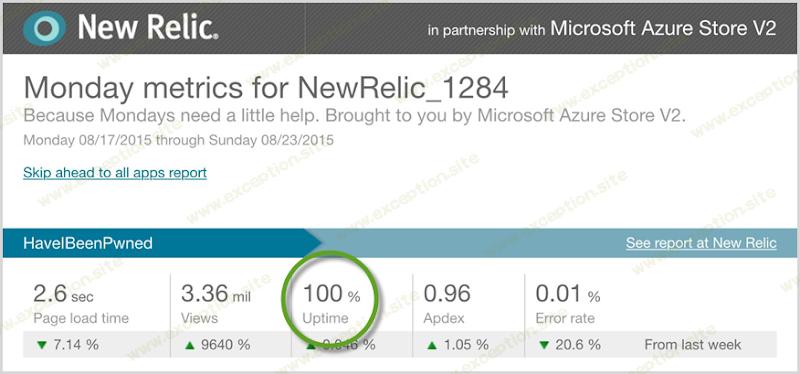
我总是喜欢努力改进事物,但正常运行时间是我永远不会超过的一个属性。 在这三个疯狂的日子里,Azure 上的 HIBP 为多达 10,000 个同时查询 2.2 亿条记录的用户提供了 400 万的页面浏览量,平均耗时 41 毫秒,同时 100.00% 的正常运行时间花费了我 130 美元!
一个完全离题的故事:当我和家人一起去雪地度假时,这一切都爆发了:

现在我绝不会错过任何下雪时间,所以每次我和儿子回到缆车上时,我都会拿出 iPhone 并启动一个 RDP 会话到我用来管理一切的 VM :
这真是太棒了:我正在世界另一端的山上骑行,同时调整支持数百万访问者搜索数亿条记录的虚拟基础设施的规模。要是缆车票能像在 Azure 上运行大型 Web 应用程序一样便宜就好了……