 异常教程
异常教程
YARN 简介
💡一则或许对你有用的小广告
欢迎加入小哈的星球 ,你将获得:专属的项目实战(已更新的所有项目都能学习) / 1v1 提问 / Java 学习路线 / 学习打卡 / 每月赠书 / 社群讨论
- 新开坑项目:《Spring AI 项目实战》 正在持续爆肝中,基于 Spring AI + Spring Boot 3.x + JDK 21..., 点击查看 ;
- 《从零手撸:仿小红书(微服务架构)》 已完结,基于
Spring Cloud Alibaba + Spring Boot 3.x + JDK 17...,点击查看项目介绍 ;演示链接: http://116.62.199.48:7070 ;- 《从零手撸:前后端分离博客项目(全栈开发)》 2 期已完结,演示链接: http://116.62.199.48/ ;
截止目前, 星球 内专栏累计输出 100w+ 字,讲解图 4013+ 张,还在持续爆肝中.. 后续还会上新更多项目,目标是将 Java 领域典型的项目都整一波,如秒杀系统, 在线商城, IM 即时通讯,权限管理,Spring Cloud Alibaba 微服务等等,已有 3700+ 小伙伴加入学习 ,欢迎点击围观
与 Hadoop 1.x 相比,YARN/Hadoop 2.x 具有完全不同的架构。
在 Hadoop 1.x 中,JobTracker 有两个主要功能:
- 资源管理
- 作业调度/作业监控
回想一下,在 Hadoop 1.x 中,每个 Hadoop 集群都有一个 JobTracker 服务于这些功能,其中扩展可以压倒 JobTracker。此外,只有一个 JobTracker 会使其成为单点故障;如果 JobTracker 宕机,整个集群和所有当前作业一起宕机。
YARN 试图将上述功能分成两个守护进程:
- 全球资源经理
- 每个应用程序应用程序主机
在 YARN 之前,Hadoop 被设计为仅支持 MapReduce 作业。随着时间的推移,人们遇到了 MapReduce 无法解决的大数据计算问题,因此想出了在 HDFS 之上工作的不同框架来解决他们的问题。其中一些是:
-
阿帕奇星火
-
阿帕奇哈马
-
阿帕奇吉拉夫。
YARN 为这些新框架提供了一种集成到 Hadoop 框架中的方法,共享相同的底层 HDFS。 YARN 使 Hadoop 能够处理 MapReduce 之外的作业。
YARN 架构概述
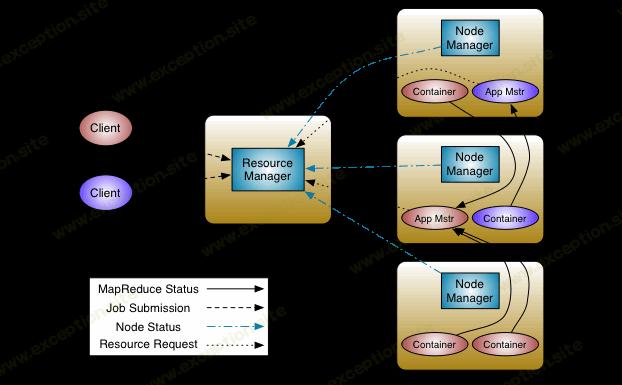 纱线架构。 [图片来源'http://hadoop.apache.org/']
纱线架构。 [图片来源'http://hadoop.apache.org/']
纱线组件
如前所述,随着架构的翻新,YARN 引入了一套我们必须熟悉的全新术语。
YARN 使用术语“应用程序”而不是 Hadoop 1.x 中使用的术语“作业”。在 YARN 中,应用程序可以是单个作业或作业的有向无环图 (DAG),并且应用程序不一定必须是 MapReduce 类型。应用程序是特定应用程序类型的实例,它与应用程序主机相关联。对于每个应用程序,都会启动一个 ApplicationMaster 实例。
YARN 组件包括:
- 容器
- 全球资源经理
- 每节点节点管理器
- 每个应用程序应用程序主机
让我们一一了解每个组件。
容器
容器是一个工作单元发生的地方。例如,每个 MapReduce 任务(不是整个作业)都在一个容器中运行。应用程序/作业将在一个或多个容器上运行。为每个容器分配一组物理资源,目前支持 CPU 内核和 RAM。 Hadoop 集群中的每个节点都可以运行多个容器。
全球资源经理
资源管理器由两个主要元素组成;
- 调度程序
- 应用程序管理器
可插拔调度程序负责为正在运行的应用程序分配资源。调度资源是根据应用程序的资源需求来完成的,并确保最佳的资源利用率。可插入调度程序的示例包括 Capacity Scheduler 和 Fair Scheduler 。
Application Master 做几项工作;
- 接受客户端程序提交的作业。
- 协商第一个容器以执行每个应用程序的 Application Master。
- 提供重新启动失败的 Application Master 容器的服务。
正如您在 Hadoop 1.x 中所记得的那样,JobTracker 处理重新启动失败的任务并监视每个任务的状态。正如您在 YARN 中观察到的那样,ResourceManager 不处理任何这些任务,而是委托给一个名为 per-application Application Master 的不同组件,我们稍后会遇到它。这种分离使得 ResourceManager 成为分配资源的最终权威,并且它还降低了 ResourceManager 的负载并使其具有比 JobTracker 更大的扩展性。
您可能已经注意到全局资源管理器可能是单点故障。在 2.4 版本之后,Hadoop 引入了高可用性 Resource Manager 概念,通过 Active/Standby ResourceManager 对来消除这种单点故障。您可以从此 链接 阅读更多相关信息。
每节点节点管理器
节点管理器是实际为应用程序提供资源的组件。 NodeManager 守护进程是运行在 Hadoop 集群中每个计算节点上的从属服务。
NodeManager 从 ResourceManager 获取资源请求并将容器提供给应用程序。 NodeManager 跟踪每个节点的健康状况并定期向 ResourceManager 报告,以便 ResourceManager 可以跟踪全局健康状况。
在每个节点启动期间,它们向 ResourceManager 注册并让它知道可用资源的数量。此信息会定期更新。
NodeManager 管理资源并定期向 ResourceManager 报告节点状态,但它对应用程序状态一无所知。应用程序由一个名为 ApplicationMaster 的不同组件处理,我们将在接下来进行讨论。
每个应用程序应用程序管理器
ApplicationMaster从ResourceManager协商执行应用程序所需的资源容器,从NodeManager获取资源并执行应用程序。对于实际上是特定应用程序类型实例的每个应用程序,都会启动一个 ApplicationManager 实例。
在 Hadoop 1.x 中,当任务失败时,JobTracker 负责重新执行该任务,这会增加 JobTracker 的负载并降低其可扩展性。
在 Hadoop 2.x 中,ResourceManager 只负责调度资源。 ApplicationMaster 负责从 ResourceManager 协商资源容器,如果任务失败,ApplicationMaster 从 ResourceManager 协商资源并尝试重新执行失败的任务。
Hadoop 1.x 仅支持 MapReduce 类型的作业,因为其设计紧耦合以解决 MapReduce 类型的计算。相比之下,Hadoop 2.x 具有更可插入的架构,并支持在底层使用 HDFS 的新框架。通过开发 ApplicationMaster 可以插入一个新的框架并与 Hadoop 框架一起玩。
YARN 如何处理客户端请求?
当客户端程序向YARN框架提交应用程序时,ApplicationMaster是根据应用程序类型决定的。 ResourceManager 与 NodeManager 协商获得一个 Container 来执行 ApplicationMaster 的一个实例。启动 ApplicationMaster 实例后,它会向 ResourceManager 注册。 Client 通过 ResourceManager 与 ApplicationMaster 通信。 ApplicationMaster 与ResourceManager 协商特定节点的资源,并从NodeManager 获取最有可能是该特定节点的实际资源。在容器上运行的应用程序代码定期向 ApplicationMaster 报告它们的状态。作业完成后,AppMaster 向 ResourceManager 注销并释放使用的容器。
HDFS 高可用性
在 Hadoop 1.x 中,只有一个 NameNode,这使其成为单点故障。如果 NameNode 发生故障,整个集群将无法访问。为避免这种麻烦,Hadoop 2.x 引入了高可用性 NameNode 概念,即使用 Active/Standby NameNode 对。在高层,当 Active NameNode 服务于客户端请求时,Standby NameNode 不断与 Active NameNode 同步。如果 Active NameNode 出现故障,Standby NameNode 将成为 Active NameNode 并继续为客户端请求提供服务。您可以从 此处 深入阅读详细信息。