 异常教程
异常教程
样条提升的更新
💡一则或许对你有用的小广告
欢迎加入小哈的星球 ,你将获得:专属的项目实战 / 1v1 提问 / Java 学习路线 / 学习打卡 / 每月赠书 / 社群讨论
- 新项目:《从零手撸:仿小红书(微服务架构)》 正在持续爆肝中,基于
Spring Cloud Alibaba + Spring Boot 3.x + JDK 17...,点击查看项目介绍 ;- 《从零手撸:前后端分离博客项目(全栈开发)》 2 期已完结,演示链接: http://116.62.199.48/ ;
截止目前, 星球 内专栏累计输出 82w+ 字,讲解图 3441+ 张,还在持续爆肝中.. 后续还会上新更多项目,目标是将 Java 领域典型的项目都整一波,如秒杀系统, 在线商城, IM 即时通讯,权限管理,Spring Cloud Alibaba 微服务等等,已有 2900+ 小伙伴加入学习 ,欢迎点击围观
在我之前的帖子 “尝试理解提升算法” 中,当我使用一些样条函数(更具体地说是按部分线性和连续回归函数)时,我对提升收敛感到困惑。我在用
> library(splines) > fit=lm(y~bs(x,degree=1,df=3),data=df)该样条函数的问题在于节点似乎是固定的。迭代提升算法是
-
从一些回归模型开始
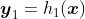
-
计算残差,包括一些收缩参数,
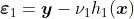
那么策略就是对这些残差进行建模
-
在步骤
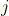 , 考虑回归
, 考虑回归
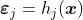
-
更新残差
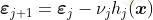
并循环。然后设置
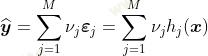
我认为如果按步骤进行提升会很好
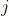 , 可以改变结。但是输出
, 可以改变结。但是输出
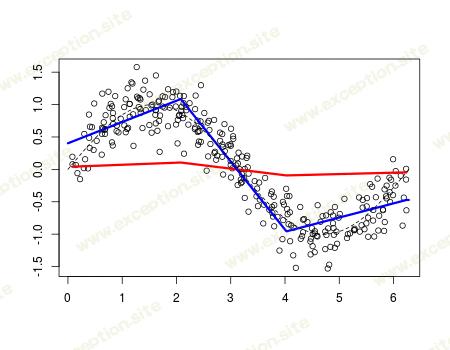
非常令人失望:提升并不能改善这里的预测。看起来结没有改变。实际上,如果我们选择“ 最佳 ”节点,输出会好得多。数据集还在
> n=300 > set.seed(1) > u=sort(runif(n)*2*pi) > y=sin(u)+rnorm(n)/4 > df=data.frame(x=u,y=y)对于节点位置的最佳选择,我们可以使用
> library(freeknotsplines) > xy.freekt=freelsgen(df$x, df$y, degree = 1, + numknot = 2, 555)上一篇文章的代码可以简单地更新
> v=.05 > library(splines) > xy.freekt=freelsgen(df$x, df$y, degree = 1, + numknot = 2, 555) > fit=lm(y~bs(x,degree=1,knots= + xy.freekt@optknot),data=df) > yp=predict(fit,newdata=df) > df$yr=df$y - v*yp > YP=v*yp > for(t in 1:200){ + xy.freekt=freelsgen(df$x, df$yr, degree = 1, + numknot = 2, 555) + fit=lm(yr~bs(x,degree=1,knots= + xy.freekt@optknot),data=df) + yp=predict(fit,newdata=df) + df$yr=df$yr - v*yp + YP=cbind(YP,v*yp) + } > nd=data.frame(x=seq(0,2*pi,by=.01)) > viz=function(M){ + if(M==1) y=YP[,1] + if(M>1) y=apply(YP[,1:M],1,sum) + plot(df$x,df$y,ylab="",xlab="") + lines(df$x,y,type="l",col="red",lwd=3) + fit=lm(y~bs(x,degree=1,df=3),data=df) + yp=predict(fit,newdata=nd) + lines(nd$x,yp,type="l",col="blue",lwd=3) + lines(nd$x,sin(nd$x),lty=2)} > viz(100)
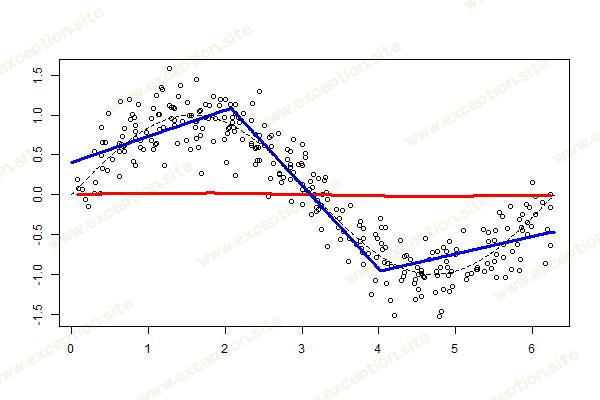
我喜欢那个图表。我的直觉是使用(简单的)样条曲线是可能的,事实上,我们得到了一个非常平滑的预测。