 异常教程
异常教程
MySQL 5.7 与 Tungsten 中的多源复制
💡一则或许对你有用的小广告
欢迎加入小哈的星球 ,你将获得:专属的项目实战(已更新的所有项目都能学习) / 1v1 提问 / Java 学习路线 / 学习打卡 / 每月赠书 / 社群讨论
- 新开坑项目:《Spring AI 项目实战》 正在持续爆肝中,基于 Spring AI + Spring Boot 3.x + JDK 21..., 点击查看 ;
- 《从零手撸:仿小红书(微服务架构)》 已完结,基于
Spring Cloud Alibaba + Spring Boot 3.x + JDK 17...,点击查看项目介绍 ;演示链接: http://116.62.199.48:7070 ;- 《从零手撸:前后端分离博客项目(全栈开发)》 2 期已完结,演示链接: http://116.62.199.48/ ;
截止目前, 星球 内专栏累计输出 100w+ 字,讲解图 4013+ 张,还在持续爆肝中.. 后续还会上新更多项目,目标是将 Java 领域典型的项目都整一波,如秒杀系统, 在线商城, IM 即时通讯,权限管理,Spring Cloud Alibaba 微服务等等,已有 3700+ 小伙伴加入学习 ,欢迎点击围观
MySQL 5.7 带来了一组新的特性,多源复制就是其中之一。简而言之,这意味着一个 slave 可以同时从不同的 master 复制。
在过去的几个月里,我一直在研究这个问题,试图在我与客户合作时遇到的真实案例中分析它的潜力。
这是有动机的,因为我的客户已经在使用带有 Tungsten Replicator 的多源从站,我想在 MySQL 5.7 中对 Tungsten Replicator 和多源复制进行并排比较
考虑以下场景

DB1 是我们的主要主机,主要处理来自多个应用程序的写入,它还需要服务读取流量,这使其容量接近极限。它使用常规复制附加了 6 个复制从站。
A1、A2、A3、B1、B2 和 DB7 是报告从属,用于从主控卸载一些读取,并且还在一些离线 ETL 过程中唤醒。
由于他们有一些空闲容量,客户决定更进一步并设置不同的架构:
A1 和 B1 也成为使用 Tungsten Replicator 的其他从站的主人,在这种情况下,组 A 是一组用于统计应用程序的服务器,B 正在参与财务应用程序,因此 A2、A3 和 B2 成为多源从站。
新应用程序直接写入 A1 和 B1,而不会影响主 master 的写入容量。
这种方法的优缺点
优点
- 它只是工作。我们已经以这种方式运行了很长时间,并且没有遇到重大问题。
- Tungsten Replicator 有一些内置的工具和脚本来简化从站的配置。
缺点
- Tungsten Replicator 是一个很棒的产品,但比这个架构需要的更大。在某些情况下,我们必须为 Java 虚拟机配置 4GB RAM 才能使其正常工作。
- Tungsten 是一个复杂的工具,需要一些额外的专业知识来部署它,使其工作并在发生错误时解决问题(即处理重复键错误)
考虑到所有这些,我们向前迈进了一步,开始测试我们是否可以将此架构移动到仅使用遗留复制。
新架构设计
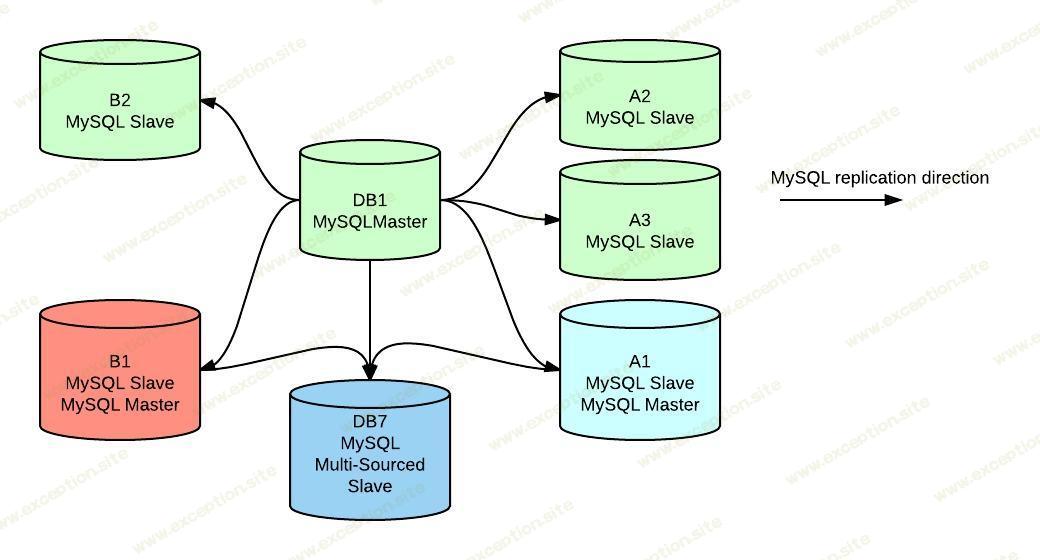
我们为测试目的向 DB7 添加了一些存储容量,这里的目标是用所有数据库都整合的单个服务器替换所有 Tungsten 复制的从服务器。
对于某些数据依赖性,我们无法将 A1 和 B1 服务器完全分开以成为仅主服务器,因此它们目前充当 DB7 的主服务器和 DB1 的从服务器通过数据依赖,我的意思是 DB1 将其模式复制到所有直接从服务器,包括 DB7。 DB7 还将本地运行的财务数据库复制到 B1,将本地运行的统计数据库复制到 A1。
这是如何完成的,以及实现了什么多源
- 常规复制之间的主要区别,正如 5.6 版本所知道的那样,现在你有复制通道,每个通道意味着不同的源,换句话说,每个 master 都有自己的复制通道。
-
复制需要设置为崩溃安全,这意味着
master_info_repository和relay_log_info_repository变量都需要设置为TABLE - 我们没有考虑 GTID,因为充当主服务器的服务器与我们的测试多源从服务器具有不同的版本。
-
需要在 A1 和 B2 中禁用
log_slave_updates,以避免由于复制流在 DB7 中出现重复数据。
这种方法的优缺点
优点
- MySQL 5.7 可以从不同版本的 master 复制,我们测试了多源复制同时与 5.5 和 5.6 一起工作,除了基于时间戳的字段的已知更改之外没有遇到问题。
- 管理变得更容易。任何已经熟悉遗留复制的 DBA 都可以适应处理多个通道而无需太多学习,一些新变量和几个新表,你已经准备好去这里了。
缺点
- 5.7 尚未准备好生产。目前我们没有 GA 发布数据,这意味着我们可能会在短期/中期出现错误。
-
对于某些特殊情况,多源仍然很棘手:数据库和表过滤在全局范围内工作(不能设置每个通道的过滤器)并且像
sql_slave_skip_counter这样的管理命令仍然是一个全局命令,这意味着你不能轻易地跳过特定的语句渠道。
现在是有趣的部分:如何
这比你想象的要容易。首先,我们需要从我们的主人的数据备份开始。由于生产中使用的版本(主 master 是 5.5,A1 和 B1 是 5.6)我们从逻辑转储开始,所以我们避免处理 mysql_upgrade 问题。
免责声明:这并不是关于如何设置多源复制的指南
对于我们的案例,我们使用 mydumper/myloader 进行了备份/恢复,如下所示:
[root@db1]$ mydumper -l 600 -v 3 -t 8 --outputdir /mnt/backup_db1/20150708 --less-locking --regex="^(database1.|database2.|database3.)"
[root@a1]$ mydumper -l 600 -v 3 -t 8 --outputdir /mnt/backup_a1/20150708 --less-locking --regex="^(tungsten_stats.|stats.)"
[root@b1]$ mydumper -l 600 -v 3 -t 8 --outputdir /mnt/backup_b1/20150708 --less-locking --regex="^(tungsten_finance.|finance.)"
请注意,每个命令都在每个主服务器中运行,现在是恢复部分:
[root@db1]$ mydumper -l 600 -v 3 -t 8 --outputdir /mnt/backup_db1/20150708 --less-locking --regex="^(database1.|database2.|database3.)"
[root@a1]$ mydumper -l 600 -v 3 -t 8 --outputdir /mnt/backup_a1/20150708 --less-locking --regex="^(tungsten_stats.|stats.)"
[root@b1]$ mydumper -l 600 -v 3 -t 8 --outputdir /mnt/backup_b1/20150708 --less-locking --regex="^(tungsten_finance.|finance.)"
所以在这一点上我们有一个新的奴隶,有来自 3 个不同主人的数据库副本,只是为了上下文我们需要转储/恢复 tungsten* 数据库,因为它们由 Replicator 不断更新(此时仍在使用)。很容易吧?
现在是整个过程中最重要的部分,设置复制。该过程与常规复制非常相似,但现在我们需要考虑每个复制通道需要哪个 binlog 位置,这很容易从每个备份中获取,在本例中通过读取 mydumper 创建的元数据文件。在已知的备份方法(无论是逻辑的还是物理的)中,您有一种获取二进制日志坐标的方法,例如 mysqldump 中的 –master-data=2 或 xtrabackup 中的 xtrabackup_binlog_info 文件。
一旦我们获得了复制信息(并在 master 中创建了一个复制用户),那么我们只需要运行已知的
CHANGE MASTER TO
和
START SLAVE
命令,但这里我们有新的方法来做到这一点:
[root@db1]$ mydumper -l 600 -v 3 -t 8 --outputdir /mnt/backup_db1/20150708 --less-locking --regex="^(database1.|database2.|database3.)"
[root@a1]$ mydumper -l 600 -v 3 -t 8 --outputdir /mnt/backup_a1/20150708 --less-locking --regex="^(tungsten_stats.|stats.)"
[root@b1]$ mydumper -l 600 -v 3 -t 8 --outputdir /mnt/backup_b1/20150708 --less-locking --regex="^(tungsten_finance.|finance.)"
复制已设置,现在我们可以开始了:
[root@db1]$ mydumper -l 600 -v 3 -t 8 --outputdir /mnt/backup_db1/20150708 --less-locking --regex="^(database1.|database2.|database3.)"
[root@a1]$ mydumper -l 600 -v 3 -t 8 --outputdir /mnt/backup_a1/20150708 --less-locking --regex="^(tungsten_stats.|stats.)"
[root@b1]$ mydumper -l 600 -v 3 -t 8 --outputdir /mnt/backup_b1/20150708 --less-locking --regex="^(tungsten_finance.|finance.)"
新命令包括用于独立处理复制通道的
FOR CHANNEL 'channel_name'
选项
此时我们有一个从不同源运行 3 个复制通道的从站,我们可以使用我们已知的命令
SHOW SLAVE STATUS
(TL;DR) 检查复制状态
[root@db1]$ mydumper -l 600 -v 3 -t 8 --outputdir /mnt/backup_db1/20150708 --less-locking --regex="^(database1.|database2.|database3.)"
[root@a1]$ mydumper -l 600 -v 3 -t 8 --outputdir /mnt/backup_a1/20150708 --less-locking --regex="^(tungsten_stats.|stats.)"
[root@b1]$ mydumper -l 600 -v 3 -t 8 --outputdir /mnt/backup_b1/20150708 --less-locking --regex="^(tungsten_finance.|finance.)"
是的,我知道,输出太大,Oracle 人员也注意到了这一点,因此他们在 performance_schema 数据库中创建了一组新表,以帮助我们以友好的方式检索此信息,请查看此
链接
以获取更多信息。例如,我们还可以运行
SHOW SLAVE STATUS FOR CHANNEL 'b1_slave'
测试期间发现的一些限制
- 如前所述,一些配置仍然是全局的,不能为每个复制通道设置,例如复制过滤器可以在不重新启动 MySQL 的情况下设置,但它们会影响所有复制通道,如您 在此处看到的那样。
- 复制事件以某种方式在从属端序列化,就像尚未详细记录的全局计数器一样。实际上,这意味着您在解决问题时需要非常小心,因为您可能会遇到意想不到的问题,例如,如果您有 2 个复制通道因重复键错误而失败,那么即使您在运行 set global 时也会跳过哪个也不容易预测sql_slave_skip_counter=1
结论
到目前为止,这个新功能看起来非常好,并为从服务器提供了一些额外的灵活性,当我们想要将来自不同来源的数据库整合到单个服务器中时,这有助于降低体系结构的复杂性。经过一段时间的测试后,我会说在这种情况下我更喜欢这种类型的复制而不是 Tungsten Replicator,因为它易于管理,即 pt-table-checksum 和 pt-table-sync 将在没有适当限制 Tungsten 的情况下工作。
除了一些需要解决的限制外,我相信这个新特性正在改变游戏规则,并且肯定会让 DBA 的生活更轻松。我还有很多东西要测试,但这对以后的帖子很重要。
由 Franciso Bordenave 撰写。