 异常教程
异常教程
如何找到简单有趣的数 GB 数据集
💡一则或许对你有用的小广告
欢迎加入小哈的星球 ,你将获得:专属的项目实战 / 1v1 提问 / Java 学习路线 / 学习打卡 / 每月赠书 / 社群讨论
- 新项目:《从零手撸:仿小红书(微服务架构)》 正在持续爆肝中,基于
Spring Cloud Alibaba + Spring Boot 3.x + JDK 17...,点击查看项目介绍 ;- 《从零手撸:前后端分离博客项目(全栈开发)》 2 期已完结,演示链接: http://116.62.199.48/ ;
截止目前, 星球 内专栏累计输出 82w+ 字,讲解图 3441+ 张,还在持续爆肝中.. 后续还会上新更多项目,目标是将 Java 领域典型的项目都整一波,如秒杀系统, 在线商城, IM 即时通讯,权限管理,Spring Cloud Alibaba 微服务等等,已有 2800+ 小伙伴加入学习 ,欢迎点击围观
许多人对大数据非常兴奋。他们喜欢在这个边疆玩耍、探索、工作和学习。这些人很可能使用或想使用大量数据(数百 GB 甚至 TB)。但问题是,要找到数 GB 的数据集并不容易。通常,需要这些类型的数据集来试验新的数据处理框架(如 Apache Spark)或数据流工具(如 Apache Kafka)。在这篇博文中,我将描述并提供指向简单而强大的数 GB Stack Overflow 数据集的链接。
1. 机器学习数据集
机器学习问题有很多来源。 Kaggle 是解决这些问题的最佳来源,它们提供了大量带有代码示例的数据集。 大多数这些数据集都是干净的,可以在您的机器学习实验中使用。
在真正的数据科学家的生活中,您很可能没有干净数据的奢侈,而且输入数据的大小会产生额外的大问题。大学课程和在线课程在数据科学和机器学习方面提供的观点有限,因为它们教学生将统计和机器学习方法应用于少量干净数据。 实际上,数据科学家大部分时间都花在获取数据和清理数据上。 根据 Hal Varian(谷歌首席经济学家)的 说法,“21 世纪最性感的工作” 属于统计学家(我假设是数据科学家)。但是,他们大部分时间都在执行“清理”工作。
为了试验新的数据处理或数据流工具,您需要一个大的(比您的计算机内存可以容纳的大)和未清理的数据集。
大型和不干净的 rf 数据集将使您能够获得实际的数据处理或学习分析技能。原来这不是那么好找的。
2. 处理数据集
Kdnuggets 和 Quora 有很好的开放存储库列表:
- http://www.kdnuggets.com/datasets/index.html
- https://www.quora.com/What-kinds-of-large-datasets-open-to-the-public-do-you-analyze-the-mostly
这些列表中的大多数数据集都 非常小 ,而且在大多数情况下, 您需要来自数据集特定业务领域(例如物理或医疗保健)的特定知识。 但是,出于学习和实验目的,最好有一个来自所有人都熟悉的知名业务领域的数据集。
社交网络数据是最好的,因为人们了解这些数据集,并且他们对分析过程中重要的数据有直觉 。您可以使用社交网络 API 来提取数据集。不幸的是,您的数据集不是与其他人共享您的分析结果的最佳选择。如果能找到一个具有开放许可证的通用社交网络数据集,那就太好了。我找到了一个!
3. Stack Overflow 开放数据集
Stack Overflow 数据集是我能够找到的唯一社交开放数据集。 Stackoverflow.com 是一个关于编程的问答网站。当您必须使用您不熟悉的语言编写代码时,该网站特别有用。这种众所周知的方法称为 — Stack Overflow 驱动开发或 SDD。我相信所有从事高科技行业的人都熟悉 Stack Overflow,并且他们中的许多人都拥有该网站的帐户。
Stack Exchange Company(stackoverflow.com 的所有者)在开放式创意通用许可下发布 stackexchange 数据集。您可能会在此页面上找到最新的数据集:
https://archive.org/details/stackexchange
该数据集包含所有 stackexchange 数据,包括 Stack Overflow, 存档的总大小为 27 GB 。 未压缩数据的大小超过 1 TB。
4. 如何下载和提取数据集?
然而,这个数据集并不容易获得。 首先,您需要上传整个数据集的存档。请注意 下载速度非常慢。 他们建议使用 bittorrent 客户端下载存档,但通常会出现一些问题。在没有 bittorent 的情况下,我尝试了 3 次并花了 2 天时间下载了这个存档。接下来,您需要 解压缩大型档案 。最后,您需要使用 7z 压缩器 解压缩所需的数据子集(如 stackoverflow-Posts 或 travel.stackexchange)。如果您没有 7z 压缩器,您需要找到它并将其安装到您的机器上。
从 https://archive.org/details/stackexchange 下载存档后,提取所有与 Stack Overflow 相关的存档并解压缩每个存档(所有以 stackoverflow.com 开头的存档):
- stackoverflow.com-Posts.7z
- stackoverflow.com-PostsHistory.7z
- stackoverflow.com-评论.7z
- stackoverflow.com-Badges.7z
- stackoverflow.com-PostLinks.7z
- stackoverflow.com-Tags.7z
- stackoverflow.com-Users.7z
- stackoverflow.com-Votes.7z
结果,您将看到一组具有相同名称的 xml 文件。
5.如何使用数据集?
让我们用数据集做实验。 最有趣的文件是 Posts.xml。这个文件包含 34Gb 的未压缩数据, 大约 70% 是正文,这是来自网站的问题文本。这些数据很可能不适合您的记忆。我们可能会使用磁盘内数据操作或机器学习技术。这是使用 Apache Spark 和 MLLib 或您的自定义解决方案的好机会。
让我们看一下这个 Stack Overflow 问题在文件中的样子。
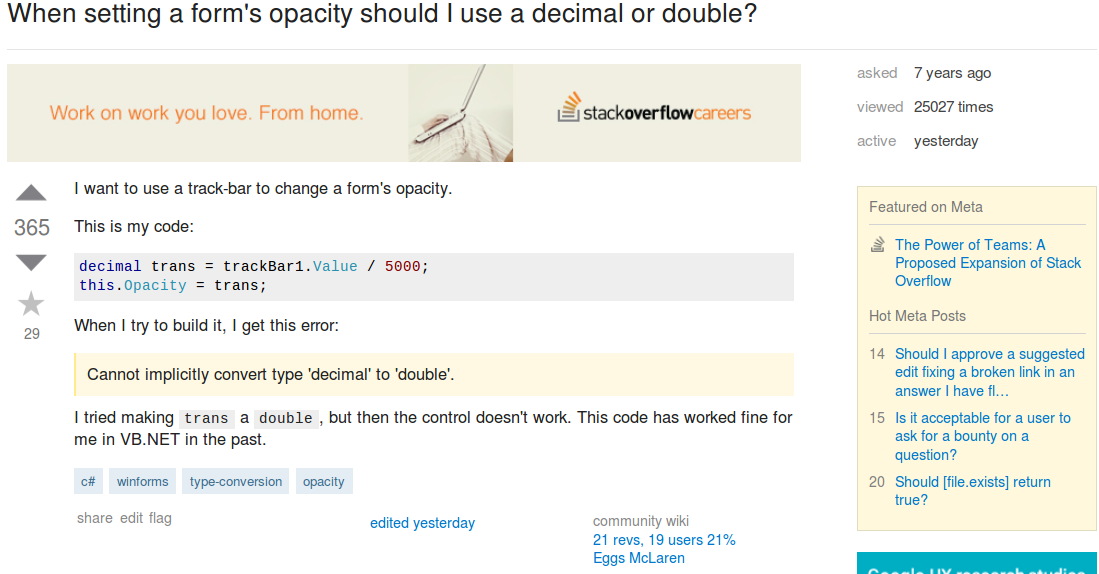
在文件中,这篇文章由一行显示。请注意,因为文本是 HTML,开始和结束 p 标签(<p> 和 </p>)被写为 <p> </p>分别。
<row>
Id=“4”
PostTypeId=“1”
AcceptedAnswerId=“7”
CreationDate=“2008-07-31T21:42:52.667”
Score=“322”
ViewCount=“21888”
Body=“<p>I want to use a track-bar to change a form’s opacity.</p> <p>This is my code:</p> <pre><code>decimal trans = trackBar1.Value / 5000; this.Opacity = trans; </code></pre> <p>When I try to build it, I get this error:</p> <blockquote> <p>Cannot implicitly convert type ‘decimal’ to ‘double’.</p> </blockquote> <p>I tried making <code>trans</code> a <code>double</code>, but then the control doesn’t work. This code has worked fine for me in VB.NET in the past. </p> ”
OwnerUserId=“8”
LastEditorUserId=“451518”
LastEditorDisplayName=“Rich B”
LastEditDate=“2014-07-28T10:02:50.557”
LastActivityDate=“2014-12-20T17:18:47.807”
Title=“When setting a form’s opacity should I use a decimal or double?”