 异常教程
异常教程
具有跨数据中心的 DNS 循环平衡的 HA
💡一则或许对你有用的小广告
欢迎加入小哈的星球 ,你将获得:专属的项目实战 / 1v1 提问 / Java 学习路线 / 学习打卡 / 每月赠书 / 社群讨论
- 新项目:《从零手撸:仿小红书(微服务架构)》 正在持续爆肝中,基于
Spring Cloud Alibaba + Spring Boot 3.x + JDK 17...,点击查看项目介绍 ;演示链接: http://116.62.199.48:7070 ;- 《从零手撸:前后端分离博客项目(全栈开发)》 2 期已完结,演示链接: http://116.62.199.48/ ;
截止目前, 星球 内专栏累计输出 90w+ 字,讲解图 3441+ 张,还在持续爆肝中.. 后续还会上新更多项目,目标是将 Java 领域典型的项目都整一波,如秒杀系统, 在线商城, IM 即时通讯,权限管理,Spring Cloud Alibaba 微服务等等,已有 3100+ 小伙伴加入学习 ,欢迎点击围观
确保 24/7 可用性是提供高质量 Web 服务的重要一点。为实现这一点,可以根据特定的应用程序模式应用不同的解决方案。例如,通过横向扩展、软件集群化和会话复制。
然而,即使是配置正确的集群也很少会因整个数据中心偶尔发生故障而停机。因此,今天我们想展示一个简单、廉价且有效的 ha 解决方案——将您的工作负载分布到多个数据中心。最近,通过新添加的多个硬件区域的 jelastic 功能,这成为可能。
为了达到最高的可用性,我们提供在不同的数据中心配置两个具有相同内容的应用程序集群,因此如果其中一个不可用,所有传入的请求将被重定向到另一个区域。为了实现这一点,我们将利用 dns 循环负载平衡作为此类 ha 实施的最经济的选择。
请注意 ,这种方法最适合在 http(s) 上工作的网站和网络应用程序。对于使用 tcp 的应用程序,需要一些额外的配置来确保它们在多个后端的正常操作。
所需配置
首先,您需要至少有两个环境,位于不同的硬件区域(实现这一点的最简单方法是使用您的应用程序克隆环境并将其迁移到另一个区域)。
作为示例,我们将使用以下拓扑:一对高可用性 nginx 负载均衡器后端的 tomcat 7 应用程序服务器启用了公共 ip 选项。
请注意,所提供的解决方案需要通过 外部 ip 地址 处理传入请求,并附加到适当的节点(即平衡器或应用程序服务器)。
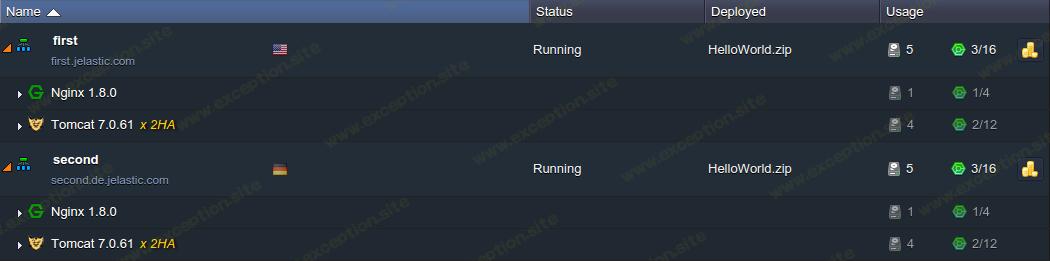 接下来,我们将受益于 dns 服务器将多个 ip 地址(即入口点)绑定到单个域名的可能性。为此,使用相应的指南将两个平衡器的外部 ip 添加到自定义域的单独记录中。
接下来,我们将受益于 dns 服务器将多个 ip 地址(即入口点)绑定到单个域名的可能性。为此,使用相应的指南将两个平衡器的外部 ip 添加到自定义域的单独记录中。
为确保一切配置正确,您可以通过终端为您的域运行以下命令来检查适当的 dns 设置:
挖掘 example.com
两个指定的记录都将以以下格式列在收到的输出的答案部分中(显然,您的域名的确切值会有所不同):
example.com 9999 在 first_ip
example.com 9999 在 second_ip
隐含的工作流程
因此,DNS 服务器将在收到对指定域的请求后发回可用地址的整个列表。相应的网络浏览器将逐个尝试并选择第一个响应的建立连接。通常,它是列表中的第一个公共 IP 地址。如果合适的数据中心不可用,将检查下一个。
请注意,标准 DNS 服务器不会跟踪所提供地址的可用性,无论其可访问性如何,都会分发整个列表。因此,如果其中一个不可用,您应该预料到请求处理会出现一些延迟,因为用户的网络浏览器将等待此类 ip 的响应一段时间(约 10-30 秒)。
另请注意,当手动从池中删除无响应地址时,它仍会暂时由 dns 服务器返回,在其 ttl 缓存设置中说明。因此,之后更改此值不会影响实际应用的参数,因此我们建议事先将其设置为最小值。
另外,dns服务器自动为多ip记录的域名提供round robin分配。因此,在处理每个请求后,地址的顺序将循环移动,将第一个 ip 向下移动,从而在不同区域的所有环境中均匀分配工作负载。
由于您的环境中的两个数据中心都不太可能同时停机,因此您已经拥有足够的冗余级别。尽管如此,通过应用类似的配置,可以轻松地进一步扩大可用区域的数量。
提示: 一些 DNS 提供商(例如亚马逊、dns made easy、dyn 等)提供额外的动态 dns 故障转移机制,其中每个记录都提供一个替代记录。原始 ip 由专门配置的 dns 服务器(如 lbnamed)监控,如果某个特定的 ip 没有响应,它将自动从池中删除并替换为适当的额外地址(仅在不可用时)。通过这种方式,您可以摆脱滞后并从所描述的 ha 方法中获益更多。
性能和故障转移测试
为了验证该解决方案的有效性,我们进行了同步故障转移检查的专项测试。为此,专用域在 apache jmeter 工具的帮助下稳定加载,同时使用嵌入式 jelastic 统计模块跟踪两个实例的变化。
首先,我们通过发送连续和持久的负载确保所有传入的请求都得到处理而没有错误。在大约 10 分钟内没有发生任何故障后,手动关闭其中一个集群以模拟故障。
在下面,您可以在运行所描述的场景期间看到我们两个负载均衡器的 CPU 和 网络 统计信息:
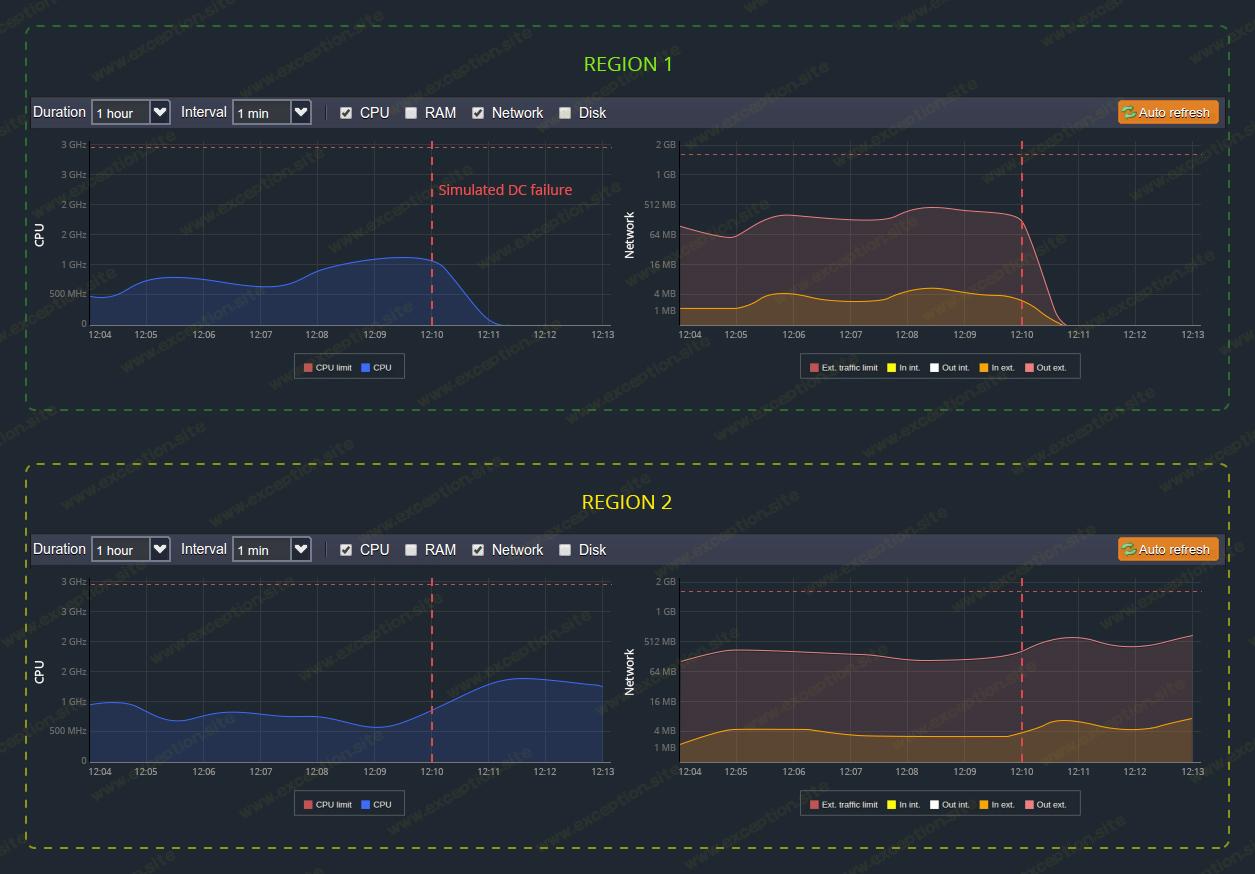
正如你所看到的,不同区域的两个环境都处理稳定且平均分配的负载,直到第一个集群收到关闭命令的时间点(大约在 12:10 - 这个时刻用红色虚线标记)。在那之后,它的活动下降到零(正如实例预期的那样,它不可用),而第二个环境的资源消耗开始上升,因为它成为唯一的入口点并且现在所有接收到的流量都在这里处理.
从上图中,您可以注意到区域 2 的网络负载在第一个区域关闭后略有增加。实际上,如此小的尖峰意味着由于该图的垂直轴使用的对数刻度而导致消耗加倍。
在第一次集群停止后,所有新传入的请求都被定向到活动实例,因此没有一个被丢弃。这可以在下面自动生成的 jmeter 报告中看到,您可以在其中检查模拟故障断点时刻的处理结果和整体测试摘要:
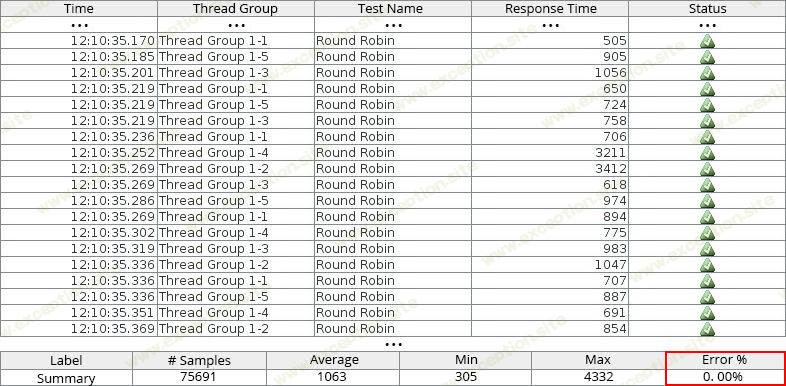
您可以使用任何其他负载生成工具(如负载影响、负载 ui、webload 等)以类似的方式自行检查所描述的 ha 方法的效率(即响应时间和错误数量)。
所提出的方法非常简单且经济实惠,因为它不需要任何额外的软硬件集成即可成功应对整个数据中心故障等重大灾难。因此,不要浪费时间,立即使用 jelastic 增加您的服务可用性和正常运行时间!尝试一下,亲自体验 jelastic devops PaaS 的所有好处。
请继续关注我们博客上即将发布的出版物,以发现另一个更高级的 ha 解决方案,该解决方案通过跟踪硬件区域的可用性来确保自动 dns 记录管理,并通过 azure 流量管理器提供传入流量的智能地理分布。请记住,与在出现问题时确保恢复丢失的数据和恢复客户的信任相比,事先采取预防措施所花费的精力和金钱总是更少。