 异常教程
异常教程
用深度学习诊断糖尿病视网膜病变
💡一则或许对你有用的小广告
欢迎加入小哈的星球 ,你将获得:专属的项目实战(已更新的所有项目都能学习) / 1v1 提问 / Java 学习路线 / 学习打卡 / 每月赠书 / 社群讨论
- 新开坑项目:《Spring AI 项目实战》 正在持续爆肝中,基于 Spring AI + Spring Boot 3.x + JDK 21..., 点击查看 ;
- 《从零手撸:仿小红书(微服务架构)》 已完结,基于
Spring Cloud Alibaba + Spring Boot 3.x + JDK 17...,点击查看项目介绍 ;演示链接: http://116.62.199.48:7070 ;- 《从零手撸:前后端分离博客项目(全栈开发)》 2 期已完结,演示链接: http://116.62.199.48/ ;
截止目前, 星球 内专栏累计输出 100w+ 字,讲解图 4013+ 张,还在持续爆肝中.. 后续还会上新更多项目,目标是将 Java 领域典型的项目都整一波,如秒杀系统, 在线商城, IM 即时通讯,权限管理,Spring Cloud Alibaba 微服务等等,已有 3700+ 小伙伴加入学习 ,欢迎点击围观
这两张图片有什么区别?
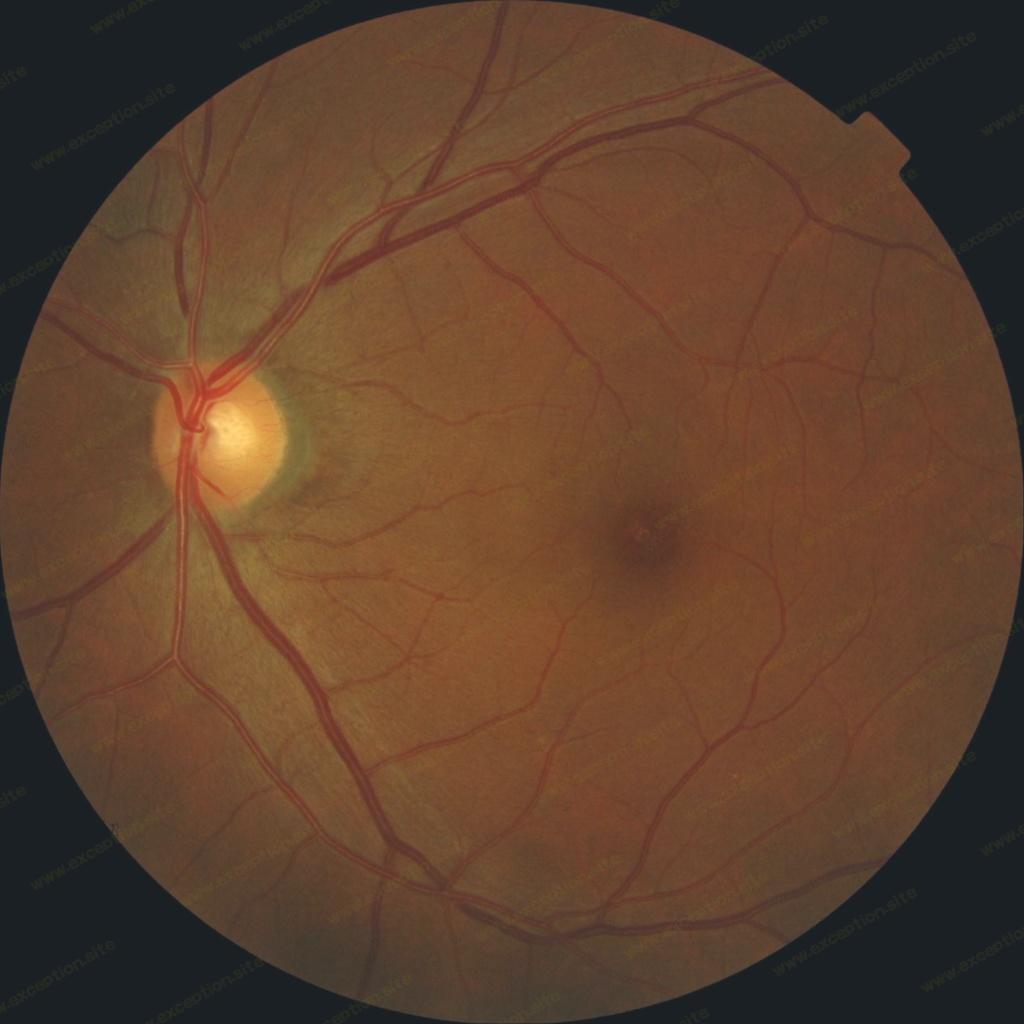
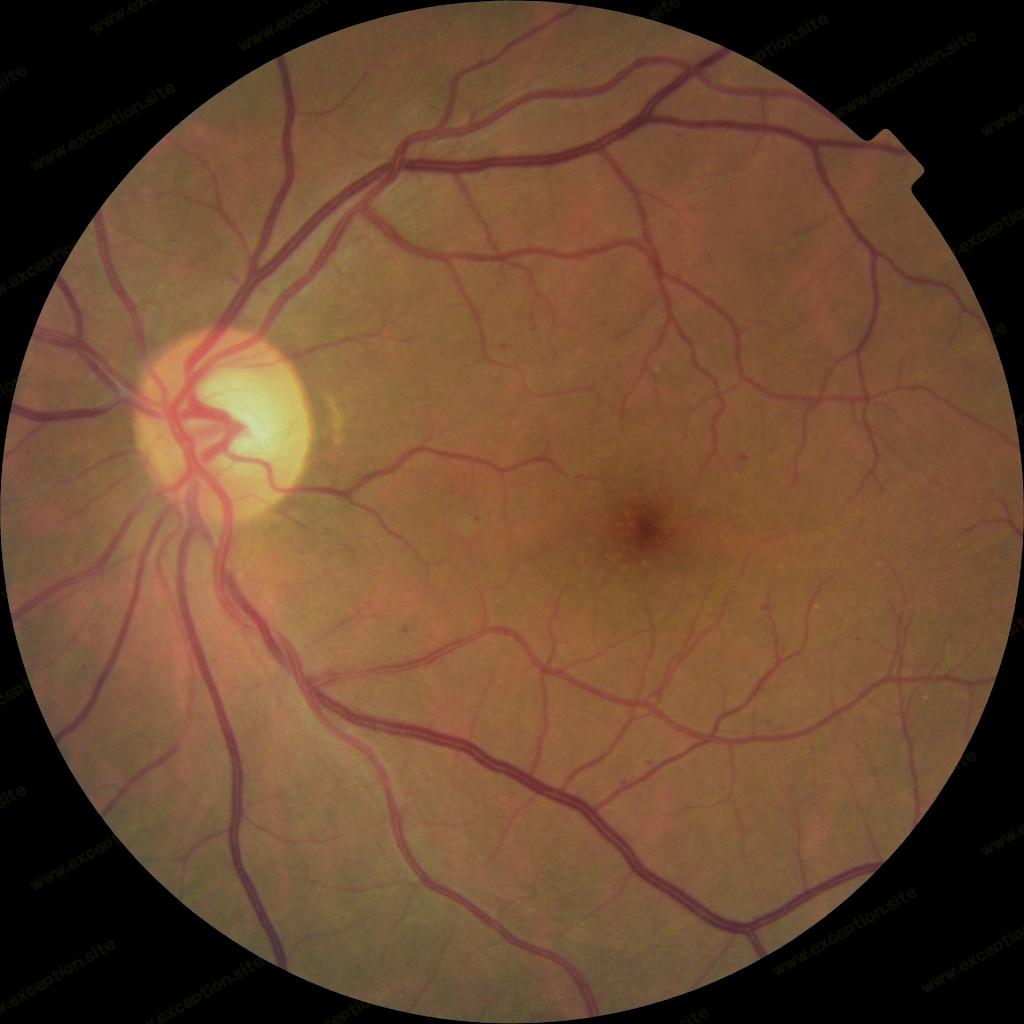
上面的一张没有糖尿病视网膜病变的迹象,而另一张则有严重的迹象。
如果您不是训练有素的临床医生,您很可能会发现很难正确识别这种疾病的体征。那么计算机程序能做到多好呢?
7 月,我们参加了 Kaggle 竞赛,目标是在提供的视网膜图像中对糖尿病性视网膜病变的严重程度进行分类。正如我们从组织者那里了解到的那样,这是一项非常重要的任务。糖尿病性视网膜病变是发达国家工作年龄人口失明的主要原因。据估计,它会影响超过 9300 万人。
比赛于 2 月开始,超过 650 支队伍参加,争夺 100,000 美元的奖池。
参赛者获得了超过 35,000 张视网膜图像,每张图像都有严重程度等级。有 5 个严重等级,等级分布相当不平衡。大多数图像没有显示出这种疾病的迹象。只有百分之几的人获得了两个最严重的评级。
对预测进行评分的指标是二次加权 kappa,我们将在后面描述。
比赛一直持续到7月底。我们队的个人积分为 0.82854,排名第六。还不错,考虑到我们很晚才进入。你可以看到我们在这个情节上的进步:

此外,您可以 在此处 阅读有关比赛的更多信息。
解决方案概述
在图像识别任务中,大多数顶级参赛者都像我们一样使用深度卷积神经网络 (CNN) 也就不足为奇了。
我们的解决方案包括多个步骤:
- 图像预处理
- 训练多个深度 CNN
- 眼睛融合
- kappa 分数优化
我们在下面简要描述了这些步骤中的每一个。在整个比赛中,我们使用了多种图像预处理方法,并训练了许多具有不同架构的网络。当集成在一起时,最佳预处理方法和最佳网络架构的收益很小。因此,我们仅限于描述单一的最佳模型。如果您不熟悉卷积网络, 请查看 Andrej Karpathy 的精彩介绍 。
预处理
主办方提供的输入图像是由非常不同的设备制作的,具有不同的尺寸和非常不同的色谱。大多数也太大而无法执行任何非平凡的模型拟合。使网络训练成为可能的最小预处理是标准化维度,但理想情况下,人们还希望标准化所有其他特征。最初,我们使用以下简单的预处理步骤:
- 将图像裁剪为包含所有高于某个阈值的像素的矩形边界框
- 将其缩放到 256×256,同时保持纵横比并填充黑色背景(原始图像或多或少也有黑色背景)
- 分别为每个 RGB 分量重新映射颜色强度,使 CDF(累积分布函数)看起来尽可能接近线性(这称为“直方图归一化”)
所有这些步骤都可以通过一次调用 ImageMagick 的命令行工具来实现。随着时间的推移,我们意识到一些输入图像包含相当密集的噪声区域。当使用上述简单的边界框裁剪时,这会导致裁剪质量不佳(即实际眼睛占据图像的任意且相当小的部分)。

您可以在图像顶部看到灰色噪声。使用最先进的边缘检测器(例如 Canny)并没有多大帮助。最终,我们开发了专门的裁剪程序。此过程自适应地选择阈值,基于对提供的图像的分析利用两个假设:
- 始终存在将噪声与眼睛轮廓分开的阈值水平。
- 眼睛的轮廓呈椭圆形,接近圆形,顶部和底部可能被截断。特别是它是一条相当平滑的曲线,可以使用这种平滑度来识别阈值的最佳值。
由此产生的裁剪器为所有图像生成了几乎理想的裁剪,这也是我们用于最终解决方案的。我们还将目标分辨率更改为 512×512,因为与较小的 256×256 分辨率相比,它似乎显着提高了我们神经网络的性能。
这是预处理图像的样子。

在将图像传递到下一阶段之前,我们对图像进行了转换,使所有图像的每个通道(R、G、B)的平均值大约为 0,标准差大约为 1。
网络架构
我们解决方案的核心是深度卷积神经网络。尽管我们从相当浅的模型开始——四个卷积层——但我们很快发现在层内添加更多层和过滤器会有所帮助。我们最好的单一模型由九个卷积层组成。
详细的架构是:
| Type | nof filters | nof units |
|---------|-------------|-----------|
| Conv | 16 | |
| Conv | 16 | |
| Pool | | |
| Conv | 32 | |
| Conv | 32 | |
| Pool | | |
| Conv | 64 | |
| Conv | 64 | |
| Pool | | |
| Conv | 96 | |
| Pool | | |
| Conv | 96 | |
| Pool | | |
| Conv | 128 | |
| Pool | | |
| Dropout | | |
| FC1 | | 96 |
| FC2 | | 5 |
| Sofmax | | |
所有 Conv 层都有 3×3 内核,步长 1 和填充 1。这样,卷积输出的大小(高度、宽度)与输入的大小相同。在我们所有的卷积层中,我们在卷积层之后是批量归一化层和 ReLu 激活。批量归一化是一种简单但功能强大的方法,用于对神经网络中的预激活值进行归一化,使其分布在训练过程中不会发生太大变化。人们经常将数据标准化以使均值和单位方差为零。批量归一化更进了一步。查看 Google 的 这篇 论文以了解更多信息。
我们的池层总是使用最大池化。池化窗口的大小为 3×3,步幅为 2。这样图像的高度和宽度就被每个池化层减半。在 FC(全连接)层中,我们再次使用 ReLu 作为激活函数。第一个全连接层 FC1 也采用批量归一化。对于正则化,我们在第一个全连接层之前使用了 Dropout 层,并将 L2 正则化应用于某些参数。总的来说,网络有 925,013 个参数。
我们使用具有动量的随机梯度下降和多类对数损失作为损失函数来训练网络。此外,学习率在训练过程中被手动调整了几次。我们使用了自己的基于 Theano 和 Nvidia cuDNN 的实现。
为了进一步规范网络,我们在训练期间通过随机裁剪 448×448 图像并以 0.5 的概率独立地水平和垂直翻转它们来扩充数据。在测试期间,我们很少进行这种随机裁剪,每只眼睛翻转一次,然后对它们进行平均预测。预测也对多个时期进行了平均。
即使对于单个网络,训练和计算测试预测也需要相当长的时间。在 g2.2xlarge AWS 实例(使用 Nvidia GRID K520)上,它花费了大约 48 小时。
眼睛融合
在某个时候,我们意识到一对中两只眼睛的分数之间的相关性非常高。例如,左眼得分与右眼得分相同的双眼百分比为 87.2%。对于 95.7% 的对,分数最多相差 1,对于 99.8% 的分数最多相差 2。这种相关性可能有两个原因。
首先是两只眼睛的视网膜受到糖尿病损害的时间相同,结构相似,因此推测它们发展视网膜病变的速度应该相似。不太明显的原因是地面实况标签是由人类产生的,可以想象人类专家更有可能根据对中另一幅图像的分数给同一图像不同的分数。
有趣的是,人们可以利用一对眼睛得分之间的这种相关性来产生更好的预测器。
一种简单的方法是分别采用左眼和右眼的预测分布 D_L 和 D_R,并使用线性混合生成新的分布,如下所示。对于左眼,我们预测 c⋅D L +(1-c)⋅D R ,类似地我们为右眼预测 c⋅D R +(1-c)⋅D L ,对于 [0, 1 中的某些 c ].我们尝试了 c = 0.7 和其他一些值。即使是这种简单的混合也能显着提高我们的 kappa 分数。然而,当我们训练神经网络而不是临时线性混合时,获得了更大的改进。该网络将两个分布(即 10 个数字)作为输入,并返回前 5 个输入的新“混合”版本。它可以使用对验证集的预测进行训练。至于架构,我们决定使用一个非常强正则化(通过 dropout)的架构,它有两个内层,每个内层有 500 个线性节点。
一个显而易见的想法是将卷积网络和混合网络集成到一个网络中。直觉上,这可能会产生更强的结果,但这样的网络也可能更难训练。不幸的是,我们未能在比赛截止日期前尝试这个想法。
Kappa优化
主办方提出的损失函数Quadratic weighted kappa (QWK),看似是视网膜病变诊断领域的标准,但从主流机器学习的角度来看,却很不一般。提交的分数被定义为 1 减去提交的总平方误差 (TSE) 与估计器的预期平方误差 (ESE) 之间的比率,该估计器随机回答与提交相同的分布( 在此处 查看更详细的描述)。
这是一个很难直接优化的损失函数。因此,我们不尝试这样做,而是使用两步程序。我们首先针对多类对数损失优化我们的模型。这给出了每个图像的概率分布。然后,我们使用基于模拟退火的优化器为每个图像选择一个标签。当然,我们不能在不知道实际标签的情况下真正优化 QWK。相反,我们通过以下方式为 QWK 定义和优化代理。回想一下 QWK = 1 – TSE/ESE。我们通过假设真实标签是从我们的预测描述的分布中提取的来估计 TSE 和 ESE,然后将这些预测代入 QWK 公式,而不是真实值。请注意,TSE 和 ESE 都被上述过程低估了。这两种影响在某种程度上相互抵消,但与排行榜分数相比,我们的 QWK 预测仍然相差很多。
也就是说,我们没有找到更好的提交方式。特别是,上述优化器优于我们尝试的所有临时方法,例如:整数舍入期望、模式等。
我们要感谢 加州医疗保健基金会 作为赞助商,感谢 EyePACS 提供图像,感谢 Kaggle 组织本次比赛。我们学到了很多东西,很高兴参与开发可能有助于诊断糖尿病性视网膜病变的工具。我们期待着解决下一个挑战。