 异常教程
异常教程
CQRS 读取模型中的持久化
💡一则或许对你有用的小广告
欢迎加入小哈的星球 ,你将获得:专属的项目实战(已更新的所有项目都能学习) / 1v1 提问 / Java 学习路线 / 学习打卡 / 每月赠书 / 社群讨论
- 新开坑项目:《Spring AI 项目实战》 正在持续爆肝中,基于 Spring AI + Spring Boot 3.x + JDK 21..., 点击查看 ;
- 《从零手撸:仿小红书(微服务架构)》 已完结,基于
Spring Cloud Alibaba + Spring Boot 3.x + JDK 17...,点击查看项目介绍 ;演示链接: http://116.62.199.48:7070 ;- 《从零手撸:前后端分离博客项目(全栈开发)》 2 期已完结,演示链接: http://116.62.199.48/ ;
截止目前, 星球 内专栏累计输出 90w+ 字,讲解图 3441+ 张,还在持续爆肝中.. 后续还会上新更多项目,目标是将 Java 领域典型的项目都整一波,如秒杀系统, 在线商城, IM 即时通讯,权限管理,Spring Cloud Alibaba 微服务等等,已有 3100+ 小伙伴加入学习 ,欢迎点击围观
cqrs 的最大好处之一是能够实现多个读取模型。业务规则和域模型在写入模型中是安全、干净和隔离的。他们不会妨碍视图模型,视图模型可以有选择地挑选他们感兴趣的部分,自由地重塑它们,并以一种需要与域模型不同的优雅和清晰度的方式来做所有事情。读取模型都是关于查询性能和便利性的。
简而言之,cqrs 是 pat helland 在他关于不变性的论文中所描述的内容的实际实现: 事实就是日志。数据库是日志子集的缓存。 让我们看一下这种方法的一些结果。
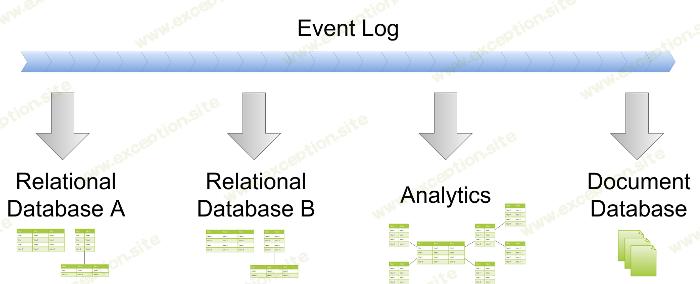
关系数据库中的持久模型
也许最明显的实现读取模型的方法是在 传统的 sql 数据库 中。这项技术已经存在了几十年,非常成熟和久经考验,每个人都熟悉它。
然而,在 cqrs 世界中,我们可以做一些在典型应用程序数据库模式中会出现问题的事情。由于我们针对读取便利性和性能进行了优化,因此数据通常是非 规范化的 。它可以通过多种方式发生:
- 可能有一些字段结合了来自其他字段的数据(例如,带有人性化街道地址的单个文本字段)。
- 相同的数据可能出现在不止一个地方,不止一张表。例如,将人类可读的街道地址放在一个列中可能是有意义的,但同时将州和城市保留在不同的列(或表)中。
- 有时保留实体的多个修订或更改历史记录也很有意义,而不仅仅是最终版本。
- 非规范化数据的另一个很好的例子是分析(如 olap 多维数据集)。
- 数据不必是相关的。您不需要将 java 对象中的字段映射到列,或将对象图映射到多个表。你可以将整个东西序列化(到 json,xml,使用本机 java 序列化等)并将它放在一个 blob 字段中。
为什么非规范化?
您可能想知道为什么一开始会使用非规范化模式。答案是:提前做更多的计算,同时处理事件并且没有人在等待答案。这意味着在人类等待答案的那一刻计算更少。
原因是人类的时间很昂贵,而且越来越贵,而计算能力和存储已经非常便宜,而且越来越便宜。值得提前进行大量计算,以节省人类一点时间。
多少非规范化?
非规范化程度主要取决于性能和查询复杂度。完全规范化的模式有它的好处,但也有很多缺点。大量的连接、计算和过滤器很快变得难以编写和维护。它们也可能成为性能噩梦,例如在大量表之间进行连接。即使您没有加入数千行,重要的计算也会让用户等待。
非规范化可用于准备查询的答案。如果查询需要通常存在于几个大表中的数据,则可以将它们组合一次(在异步投影中),然后在用户需要时以常数或对数时间查找。甚至可以走极端并预先计算对所有常见查询的响应,从而消除对更高级别缓存的需求。在这种情况下 ,视图模型是缓存 。
不过,有必要在这里寻求平衡。过于激进的反规范化会导致与代码重复相关的可维护性差,并增加数据量(以字节为单位)。
其他持久性解决方案
如果数据不必是关系数据,或者如果它可以非规范化,那么将它放在不同类型的数据库中可能是个好主意。有多种 nosql 选项可供选择,最明显的候选者是文档和键值存储。
不过,我们不必就此止步——如果数据可以从图形数据库中受益,那就没有障碍了。视图模型的另一个很好的例子是像 lucene 这样的搜索索引。
这样的商店通常有其缺点。他们可能会牺牲可用性和性能的一致性。它们可能非常专业或仅限于特定模型(图形、文档、键值等)。这使得它们作为典型的非 cqrs 读/写模型中的主要持久性机制具有挑战性,甚至不适用。然而,它们在 cqrs 视图模型中可能是完全可以接受的,并且这些优势使整个事情变得更加强大。
在记忆中
我们一直在考虑的另一个想法是内存模型。写入和读取磁盘很慢,如果数据 适合 ram ,为什么不将它保存在内存中,使用您选择的语言的普通数据结构?
有一些挑战:
- 如果事件存储足够大,读取和消费它可能需要相对较长的时间和大量资源。极限可能比乍看起来更远,但肯定是必须仔细考虑的事情。
- 它需要是事务性的。在查询读取数据时更改数据是不可接受的。您可能还需要回滚,这绝非易事。在支持事务内存或持久数据结构(如 clojure)的语言中要容易得多,并且您可能需要在其他地方使用具有此类功能的库。
这些挑战可以通过使用持久的事务性存储来解决:
- 使用领域事件时,更新内存模型。不要触摸磁盘。
- 每隔一段时间(例如每 1000 个事件或每分钟)拍摄该模型的快照并将其写入某个持久存储。
- 让查询从该持久快照中读取,可能将其缓存在内存中。
- 重新启动应用程序或出现错误后,继续使用最新快照中的事件。
它越来越接近持久性预测,但存在重要差异。在这种情况下,持久性仅用于隔离和重启后从保存点恢复的一种方式。磁盘 io 可以异步或不那么频繁地发生,而不会减慢编写器和查询的速度。
数据保留
大多数查询只对相对较新的数据感兴趣。有些可能需要一两年,有些可能只对最后一周感兴趣。源数据在域端是安全的,读取模型可以根据需要自由保留。它可以对他们的性能和存储需求产生巨大的积极影响。
也可能有许多模型具有相同的模式但数据保留不同。尽可能使用较小的数据集以获得最佳响应能力。但仍然有能力回退到更大的数据集,以偶尔查询遥远的过去,更长的响应时间是可以接受的。
这种方法可以与不同的粒度相结合:保留过去几周或几个月的所有细节,并聚合或缩小更长的时间段。
包起来
nosql 存储、分析、搜索索引、缓存等都是非常流行和有用的工具,并且它们经常以类似于 cqrs 的方式使用而不被承认。无论它们是用触发器、消息传递、轮询还是 etl 填充,最终结果都是一个新的、专门的、只读的数据视图。
但是,项目越成熟,越大,就越难引入这样的东西。它可能会变得非常昂贵,错失机会最终会导致许多问题。
如果您从一开始就拥有 cqrs,那就容易 多 了。域模型在其他地方保持安全和干净,数据的最终来源(如事件存储)也是如此。数据很容易用于消费(尤其是事件溯源)。剥离视图模型所需要做的就是将另一个消费者插入域事件。
视图模型也是非常好的创新候选者。尝试各种数据库和编程语言以及使用相同工具解决问题的不同方法真的很容易。
这篇文章也出现在 绿洲数字博客 上。