 异常教程
异常教程
使用 Apache Spark Pt 的大数据分析简介。 1个
💡一则或许对你有用的小广告
欢迎加入小哈的星球 ,你将获得:专属的项目实战(已更新的所有项目都能学习) / 1v1 提问 / Java 学习路线 / 学习打卡 / 每月赠书 / 社群讨论
- 新开坑项目:《Spring AI 项目实战》 正在持续爆肝中,基于 Spring AI + Spring Boot 3.x + JDK 21..., 点击查看 ;
- 《从零手撸:仿小红书(微服务架构)》 已完结,基于
Spring Cloud Alibaba + Spring Boot 3.x + JDK 17...,点击查看项目介绍 ;演示链接: http://116.62.199.48:7070 ;- 《从零手撸:前后端分离博客项目(全栈开发)》 2 期已完结,演示链接: http://116.62.199.48/ ;
截止目前, 星球 内专栏累计输出 90w+ 字,讲解图 3441+ 张,还在持续爆肝中.. 后续还会上新更多项目,目标是将 Java 领域典型的项目都整一波,如秒杀系统, 在线商城, IM 即时通讯,权限管理,Spring Cloud Alibaba 微服务等等,已有 3100+ 小伙伴加入学习 ,欢迎点击围观
Apache Spark 将 大数据 和 实时分析 的承诺和力量交到大众手中。考虑到这一点,让我们在此快速入门实践教程中介绍 Apache Spark 。这是 Apache Spark 的介绍,第 1 部分,共 4 部分。
这篇关于Spark的文章由四部分组成:
- 第 1 部分 Spark 简介、如何使用 shell 和 RDD。
- 第 2 部分 Spark SQL、Dataframes 以及如何使 Spark 与 Cassandra 一起工作。
- 第 3 部分 MLlib 和 Streaming 简介。
- 第 4 部分 GraphX。
这是第 1 部分。
如需完整的摘要和大纲,请访问我们的网站 Apache Spark QuickStart for real-time data-analytics 。
在 网站 上,您还可以找到更多文章和教程,例如; Java 反应式微服务培训 , 微服务架构 |微服务架构教程的领事服务发现和健康 。以及更多。一探究竟。
星火概述
开源集群计算系统 Apache Spark 发展迅速。 Apache Spark 拥有不断发展的库和框架生态系统,以支持高级数据分析。 Apache Spark 的快速成功归功于其强大的功能和易用性。与典型的
基于 MapReduce 大数据的分析
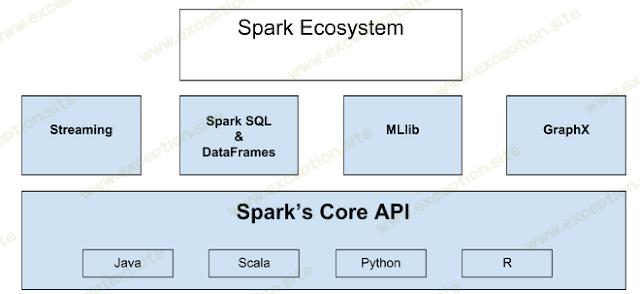
相比,它效率更高,运行时间更快。 Apache Spark 提供内存中的分布式计算。它有 Java、Scala、Python 和 R 语言的 API。Spark 生态系统如下所示。
 显示
-
编辑
显示
-
编辑
{kind=link}
整个生态系统建立在核心引擎之上。该核心支持内存计算以提高速度,其 API 支持 Java、Scala、Python 和 R。流式处理支持实时处理数据流。 Spark SQL 使用户能够查询结构化数据,您可以使用自己喜欢的语言来执行此操作,DataFrame 位于 Spark SQL 的核心,它将数据保存为行的集合,并且行中的每一列都被命名,使用 DataFrame,您可以轻松地选择、绘制和过滤数据。 MLlib 是一个机器学习框架。 GraphX 是一个用于图形结构化数据的 API。这是对生态系统的简要概述。
关于 Apache Spark 的一点历史:
-
最初于 2009 年在加州大学伯克利分校 AMP 实验室开发,于 2010 年开源,现在是顶级 Apache 软件基金会的一部分。
-
大约有 630 名贡献者提交了大约 12,500 次提交( 如 Apache Spark Github 存储库所示 )。
-
主要用 Scala 编写。
-
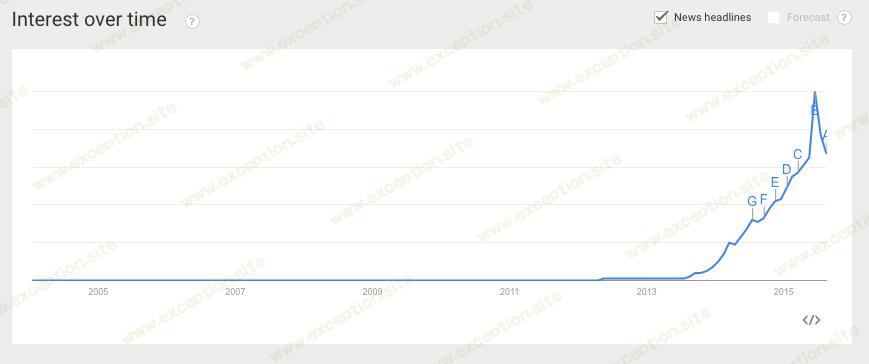
谷歌对 Apache Spark 的 搜索兴趣 最近飙升,表明人们的兴趣范围很广。 (根据 Google Ad Word Tools,7 月份的搜索量为 108,000 次,大约是 微服务的 十倍)。
-
Spark 的一些分销商:IBM、Oracle、DataStax、BlueData、Cloudera...
-
一些使用 spark 构建的应用程序:Qlik、Talen、Tresata、atscale、platfora ...
人们对 Apache Spark 如此感兴趣的原因是它让开发人员掌握了 Hadoop 的力量。设置 Apache Spark 集群比 Hadoop 集群更容易。它运行得更快。而且编程要容易得多。它将大数据和实时分析的承诺和力量交到大众手中。考虑到这一点,让我们介绍一下 阿帕奇星火 在这个快速教程中。
下载 Spark,以及如何使用交互式 Shell
试验 Apache Spark 的一个好方法是使用可用的交互式 shell。有一个 Python Shell 和一个 Scala shell。
要下载 Apache Spark,请转到 此处 ,并获取最新的预构建版本,以便我们可以开箱即用地运行 shell。
目前 Apache Spark 是 1.5.0 版,于 2015 年 9 月 9 日发布。
解压星火
tar -xvzf ~/spark-1.5.0-bin-hadoop2.4.tgz
运行 Python 外壳
tar -xvzf ~/spark-1.5.0-bin-hadoop2.4.tgz
在本节中,我们不会在此处使用 Python shell。
Scala 交互式 shell 在 JVM 上运行,因此它使您能够使用 Java 库。
运行 Scala Shell
tar -xvzf ~/spark-1.5.0-bin-hadoop2.4.tgz
你应该看到这样的东西:
Scala Shell 欢迎辞
tar -xvzf ~/spark-1.5.0-bin-hadoop2.4.tgz
下面是一个简单的练习,只是为了让您开始使用 shell。你可能不明白我们现在在做什么,但我们稍后会详细解释。使用 Scala shell ,执行以下操作:
创建一个 文本文件 RDD 来自 Spark 中的 README 文件
tar -xvzf ~/spark-1.5.0-bin-hadoop2.4.tgz
获取 RDD 文本文件中的第一个元素
tar -xvzf ~/spark-1.5.0-bin-hadoop2.4.tgz
您可以过滤RDD 文本文件 返回一个新的 RDD,其中包含包含单词的所有行 火花 ,然后计算它的行数。
过滤后的RDD 火花线 并数数它的行数
tar -xvzf ~/spark-1.5.0-bin-hadoop2.4.tgz
查找RDD中单词量最多的行 火花线 , 请执行下列操作。使用 地图 方法,将 RDD 中的每一行映射到一个数字,并查找空格。然后使用 减少 方法来查找具有最多单词的行。
在RDD中找到这一行 文本文件 那个字数最多
tar -xvzf ~/spark-1.5.0-bin-hadoop2.4.tgz
第 14 行的字数最多。
您还可以导入 Java 库,例如 数学.max() 方法因为参数 地图 和 减少 是 Scala 函数文字。
在 Scala shell 中导入 Java 方法
tar -xvzf ~/spark-1.5.0-bin-hadoop2.4.tgz
我们可以轻松地将数据缓存在内存中。
缓存过滤后的RDD 火花线 然后计算行数
tar -xvzf ~/spark-1.5.0-bin-hadoop2.4.tgz
这是关于如何使用 Spark 交互式 shell 的简要概述。
RDDs
Spark 使用户能够在集群上并行执行任务。这种并行性是通过使用 Spark 的主要组件之一 RDD 实现的。 RDD( 弹性分布式数据 )是数据的表示。 RDD 是可以 在集群上分区的 数据(如果你愿意的话,是分片数据)。分区使 任务能够并行执行 。您拥有的分区越多, 您可以执行的并行性就越多 。下图是 RDD 的表示:

{kind=link}
将每一列视为一个分区,您可以轻松地将这些分区分配给集群上的节点。
为了创建 RDD ,您可以从外部存储读取数据;例如来自 Cassandra 或 Amazon 简单存储服务、HDFS 或任何提供 Hadoop 输入格式的数据。您还可以通过读取文本文件、数组或 JSON 创建 RDD 。另一方面,如果数据是您的应用程序的本地数据,您只需要对其进行并行化,那么您将能够在其上应用所有 Spark 功能,并在 Apache Spark 集群 中进行并行分析。要对其进行测试,请使用 Scala Spark shell:
做一个RDD 事物RDD 从单词列表
tar -xvzf ~/spark-1.5.0-bin-hadoop2.4.tgz
计算RDD中的单词 事物RDD
tar -xvzf ~/spark-1.5.0-bin-hadoop2.4.tgz
为了使用 Spark, 您需要从 Spark Context 开始。当您使用 shell 时, Spark 上下文 已经存在 SC .当我们调用 并行化 在 Spark Context 上调用方法,我们将得到一个已分区并准备跨节点分布的 RDD 。
我们可以用 RDD 做什么?
使用 RDD ,我们可以转换数据或对该数据采取行动。这意味着通过转换,我们可以更改其格式、搜索内容、过滤数据等。通过您进行更改的操作,您可以提取数据、收集数据,甚至 数数() .
例如,让我们创建一个 RDD 文本文件 从文本文件 自述文件 在 Spark 中可用,此文件包含文本行。当我们将文件读入 RDD 时 文本文件 ,数据将被分割成文本行,这些文本行可以分布在集群中并并行操作。
创建RDD 文本文件 来自 README.md
tar -xvzf ~/spark-1.5.0-bin-hadoop2.4.tgz
计算行数
tar -xvzf ~/spark-1.5.0-bin-hadoop2.4.tgz
计数 98 表示中的行数 自述文件 文件。
会得到看起来像这样的东西:

{kind=link}
然后我们可以过滤掉所有有这个词的行 火花 , 并创建一个新的 RDD 火花线 包含过滤后的数据。
创建过滤后的 RDD 火花线
tar -xvzf ~/spark-1.5.0-bin-hadoop2.4.tgz
使用前面的图表,我们展示了如何 文本文件 RDD 看起来像,RDD 火花线 将如下所示:

{kind=link}
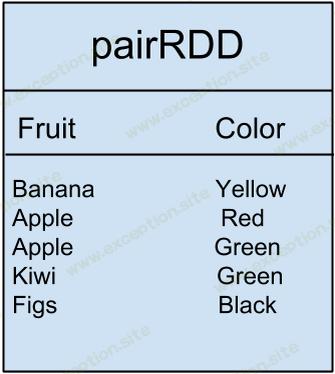
值得一提的是,我们还有所谓的 Pair RDD ,当我们有键/值配对数据时使用这种 RDD。例如,如果我们有如下表的数据,水果与其颜色相匹配:
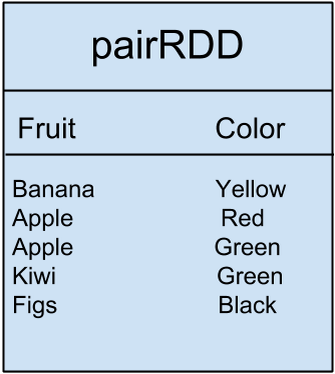{kind=link}
我们可以执行一个 分组按键() 对水果数据进行变换得到。
groupByKey() 转换
tar -xvzf ~/spark-1.5.0-bin-hadoop2.4.tgz
此转换仅将 2 个值(红色和绿色)与一个键(Apple)分组。这些是迄今为止转换变化的例子。
一旦我们过滤了一个 RDD ,我们就可以 收集/物化 它的数据并使它流入我们的应用程序,这是一个动作的例子。一旦我们这样做,RDD 中的所有数据都消失了,但我们仍然可以对 RDD 的数据调用一些操作,因为它们仍在内存中。
收集或具体化数据 火花线 RDD
tar -xvzf ~/spark-1.5.0-bin-hadoop2.4.tgz
需要注意的是,每次我们在 Spark 中调用一个动作(例如 count() 动作)时,Spark 都会遍历到该点所做的所有转换和计算,然后返回计数,这会有点慢。要解决此问题并提高性能速度,您可以 在内存中缓存 RDD 。这样当你一次又一次地调用一个动作时,你不必从头开始这个过程,你只需从内存中获取缓存的 RDD 的结果。
兑现 RDD 火花线
tar -xvzf ~/spark-1.5.0-bin-hadoop2.4.tgz
如果你想删除RDD 火花线 从内存中你可以使用 不坚持() 方法。
删除 火花线 从记忆里
tar -xvzf ~/spark-1.5.0-bin-hadoop2.4.tgz
否则, Spark 会使用最近最少使用逻辑 (LRU) 自动删除最旧的缓存 RDD。
下面是从头到尾总结 Spark 过程的列表:
-
创建某种数据的 RDD。
-
例如,通过过滤来转换 RDD 的数据。
-
如果需要重用,缓存转换或过滤的 RDD。
-
在 RDD 上做一些操作,比如拉出数据、计数、将数据存储到 Cassandra 等......
下面是一些可以在 RDD 上使用的转换的列表:
-
筛选()
-
地图()
-
样本()
-
联盟()
-
groupbykey()
-
排序键()
-
组合键()
-
键减()
-
映射值()
-
钥匙()
-
价值()
以下是可以对 RDD 执行的一些操作的列表:
-
收集()
-
数数()
-
第一的()
-
按键计数()
-
另存为文本文件()
-
减少()
-
取(n)
-
计数键()
-
collectAsMap()
-
查找(键)
有关完整列表及其描述,请查看以下 Spark 文档 。
结论
我们推出了 Apache Spark ,这是一个快速发展的开源集群计算系统。我们展示了一些支持高级数据分析的 Apache Spark 库和框架。我们展示了为什么 Apache Spark 因其强大的功能和易用性而迅速取得成功。我们演示了 Apache Spark 以提供内存中的分布式计算环境,以及它的易用性和掌握性。
回来看第 2 部分。我们将在第 2 部分深入探讨。
相关链接: