 异常教程
异常教程
学习 Apache Camel:实时索引推文
💡一则或许对你有用的小广告
欢迎加入小哈的星球 ,你将获得:专属的项目实战(已更新的所有项目都能学习) / 1v1 提问 / Java 学习路线 / 学习打卡 / 每月赠书 / 社群讨论
- 新开坑项目:《Spring AI 项目实战》 正在持续爆肝中,基于 Spring AI + Spring Boot 3.x + JDK 21..., 点击查看 ;
- 《从零手撸:仿小红书(微服务架构)》 已完结,基于
Spring Cloud Alibaba + Spring Boot 3.x + JDK 17...,点击查看项目介绍 ;演示链接: http://116.62.199.48:7070 ;- 《从零手撸:前后端分离博客项目(全栈开发)》 2 期已完结,演示链接: http://116.62.199.48/ ;
截止目前, 星球 内专栏累计输出 100w+ 字,讲解图 4013+ 张,还在持续爆肝中.. 后续还会上新更多项目,目标是将 Java 领域典型的项目都整一波,如秒杀系统, 在线商城, IM 即时通讯,权限管理,Spring Cloud Alibaba 微服务等等,已有 3700+ 小伙伴加入学习 ,欢迎点击围观
 当应用程序需要开始与其他应用程序或第 3 方组件通信时,在大多数软件开发项目中都有一个关键点。
当应用程序需要开始与其他应用程序或第 3 方组件通信时,在大多数软件开发项目中都有一个关键点。
无论是发送电子邮件通知、调用外部 API、写入文件还是将数据从一个地方迁移到另一个地方,您都可以推出自己的解决方案或利用现有框架。
至于 Java 生态系统中的现有框架,一方面是 tibco businessworks 和 mule esb ,另一方面是 spring integration 和 apache camel 。
在本教程中,我将通过一个示例应用程序向您介绍 apache camel ,该应用程序从 Twitter 的示例提要中读取推文并使用 elasticsearch 实时索引这些推文。
什么是阿帕奇骆驼?
将应用程序与生态系统中的内部或外部组件集成是软件开发中最复杂的任务之一,如果做得不好,可能会导致巨大的混乱和长期维护的真正痛苦。
幸运的是,camel——一个托管在 apache 上的开源集成框架——基于 企业集成模式 ,这些模式可以帮助编写更具可读性和可维护性的代码。类似于乐高积木,这些模式可以用作构建块来创建可靠的软件设计。
apache camel 还支持各种 连接器 ,以将您的应用程序与不同的框架和技术集成。顺便说一句,它也可以与 spring 一起很好地发挥作用。
如果您不熟悉 spring,您可能会发现这篇文章很有帮助: processing twitter feed using spring boot 。
在接下来的部分中,我们将通过一个示例应用程序,其中 camel 与 twitter 的示例提要和 elasticsearch 集成在一起。
什么是弹性搜索?
类似于 apache solr 的 elasticsearch 是一个高度可扩展的开源、基于 java 的全文搜索引擎,构建在 apache lucene 之上。
在这个示例应用程序中,我们将使用 elasticsearch 实时索引推文,并提供对这些推文的全文搜索功能。
使用的其他技术
除了 apache camel 和 elasticsearch 之外,我还在这个应用程序中包括了其他框架: gradle 作为构建工具, spring boot 作为 web 应用程序框架 ,以及 twitter4j 从 twitter 示例提要中读取推文。
入门
该项目的框架是在 http://start.spring.io 生成的,我在其中检查了 Web 依赖项选项,填写了项目元数据部分并选择了“gradle 项目”作为项目类型。
生成项目后,您可以下载并将其导入到您喜欢的ide中。我现在不打算详细介绍 gradle,但这里是 build.gradle 文件中所有依赖项的列表:
def camelversion = '2.15.2'
dependencies {
compile("org.springframework.boot:spring-boot-starter-web")
compile("org.apache.camel:camel-core:${camelversion}")
compile("org.apache.camel:camel-spring-boot:${camelversion}")
compile("org.apache.camel:camel-twitter:${camelversion}")
compile("org.apache.camel:camel-elasticsearch:${camelversion}")
compile("org.apache.camel:camel-jackson:${camelversion}")
compile("joda-time:joda-time:2.8.2")
testcompile("org.springframework.boot:spring-boot-starter-test")
}
使用骆驼路线进行整合
camel 实现了一个面向 消息的 架构,它的主要构建块是描述消息流的 路由 。
路由可以用 xml(旧方式)或其 java dsl(新方式)来描述。我们只打算在这篇文章中讨论 java dsl,因为这是首选且更优雅的选项。
好吧,那么让我们看一个简单的路线:
def camelversion = '2.15.2'
dependencies {
compile("org.springframework.boot:spring-boot-starter-web")
compile("org.apache.camel:camel-core:${camelversion}")
compile("org.apache.camel:camel-spring-boot:${camelversion}")
compile("org.apache.camel:camel-twitter:${camelversion}")
compile("org.apache.camel:camel-elasticsearch:${camelversion}")
compile("org.apache.camel:camel-jackson:${camelversion}")
compile("joda-time:joda-time:2.8.2")
testcompile("org.springframework.boot:spring-boot-starter-test")
}
这里有几点需要注意:
- 消息在由 uris 表示和配置的 端点 之间流动
-
一条路由只能有一个消息生产者端点(在本例中为
file://orders,它从 orders 文件夹中读取文件)和多个消息消费者端点:-
log:com.mycompany.order?level=debug将文件内容记录在 com.mycompany.order 日志类别下的调试消息中 -
jms:topic:orderstopic将文件内容写入 jms 主题
-
-
在端点之间可以更改消息,即
convertbodyto(string.class)将消息正文转换为字符串。
另请注意,相同的 uri 可用于一个路由中的消费者端点和另一个路由中的生产者端点:
def camelversion = '2.15.2'
dependencies {
compile("org.springframework.boot:spring-boot-starter-web")
compile("org.apache.camel:camel-core:${camelversion}")
compile("org.apache.camel:camel-spring-boot:${camelversion}")
compile("org.apache.camel:camel-twitter:${camelversion}")
compile("org.apache.camel:camel-elasticsearch:${camelversion}")
compile("org.apache.camel:camel-jackson:${camelversion}")
compile("joda-time:joda-time:2.8.2")
testcompile("org.springframework.boot:spring-boot-starter-test")
}
直接端点是通用端点之一,它允许将消息从一条路由同步传递到另一条路由。
这有助于创建可读代码并在代码的多个位置重用路由。
索引推文
现在让我们看一下代码中的一些路由。让我们从简单的事情开始:
def camelversion = '2.15.2'
dependencies {
compile("org.springframework.boot:spring-boot-starter-web")
compile("org.apache.camel:camel-core:${camelversion}")
compile("org.apache.camel:camel-spring-boot:${camelversion}")
compile("org.apache.camel:camel-twitter:${camelversion}")
compile("org.apache.camel:camel-elasticsearch:${camelversion}")
compile("org.apache.camel:camel-jackson:${camelversion}")
compile("joda-time:joda-time:2.8.2")
testcompile("org.springframework.boot:spring-boot-starter-test")
}
这很简单,对吧?到现在为止,您可能已经想到此路由从 Twitter 示例提要中读取推文并将它们传递到
direct:tweet-indexer-es
端点。请注意,
consumerkey
、
consumersecret
等已配置并作为系统属性传入(请参阅
http://twitter4j.org/en/configuration.html
)。
现在让我们看一个稍微复杂一点的路由,它从
direct:tweet-indexer-es
端点读取并批量插入推文到 elasticsearch(每个步骤的详细解释见注释):
def camelversion = '2.15.2'
dependencies {
compile("org.springframework.boot:spring-boot-starter-web")
compile("org.apache.camel:camel-core:${camelversion}")
compile("org.apache.camel:camel-spring-boot:${camelversion}")
compile("org.apache.camel:camel-twitter:${camelversion}")
compile("org.apache.camel:camel-elasticsearch:${camelversion}")
compile("org.apache.camel:camel-jackson:${camelversion}")
compile("joda-time:joda-time:2.8.2")
testcompile("org.springframework.boot:spring-boot-starter-test")
}
这条路线注意事项:
-
elasticsearchtweeturi是一个字段,其值由 spring 从application.properties文件 (elasticsearch.tweet.uri=elasticsearch://tweet-indexer?operation=bulk_index&ip=127.0.0.1&port=9300) 中获取并注入到字段中 - 要在路由中实现自定义处理逻辑,我们可以创建实现处理器接口的类。请参阅 weeklyindexnameheaderupdater 和 elasticsearchtweetconverter 。
- 使用自定义 列表聚合 策略聚合推文,该策略将消息聚合到数组列表中,稍后每 2 秒(或应用程序停止时)传递到下一个端点。
-
camel 实现了一种
表达式语言
,我们用它来记录批处理的大小 (
${body.size()}) 和从中插入消息的索引的名称 (${headers.indexname})。
在 elasticsearch 中搜索推文
现在我们已经在 elasticsearch 中索引了推文,是时候对它们进行一些搜索了。
首先让我们看一下接收搜索查询的路由和限制搜索结果数量的 maxsize 参数:
def camelversion = '2.15.2'
dependencies {
compile("org.springframework.boot:spring-boot-starter-web")
compile("org.apache.camel:camel-core:${camelversion}")
compile("org.apache.camel:camel-spring-boot:${camelversion}")
compile("org.apache.camel:camel-twitter:${camelversion}")
compile("org.apache.camel:camel-elasticsearch:${camelversion}")
compile("org.apache.camel:camel-jackson:${camelversion}")
compile("joda-time:joda-time:2.8.2")
testcompile("org.springframework.boot:spring-boot-starter-test")
}
当消息传递到
vm:tweetsearch
端点(它使用内存队列异步处理消息)时,将触发此路由。
searchcontroller
类
实现了一个 rest api,允许用户通过使用 camel 的
producertemplate
类向
vm:tweetsearch
端点发送消息来运行推文搜索:
def camelversion = '2.15.2'
dependencies {
compile("org.springframework.boot:spring-boot-starter-web")
compile("org.apache.camel:camel-core:${camelversion}")
compile("org.apache.camel:camel-spring-boot:${camelversion}")
compile("org.apache.camel:camel-twitter:${camelversion}")
compile("org.apache.camel:camel-elasticsearch:${camelversion}")
compile("org.apache.camel:camel-jackson:${camelversion}")
compile("joda-time:joda-time:2.8.2")
testcompile("org.springframework.boot:spring-boot-starter-test")
}
这将触发 elasticsearch 的执行,但是结果不会在响应中返回,而是写入
/tmp
文件夹中的文件(如前所述)。
此路由使用
elasticsearchservice
类
在 elasticsearch 中搜索推文。执行此路由时,camel 调用
search()
方法并将搜索查询和
maxsize
作为输入参数传递:
def camelversion = '2.15.2'
dependencies {
compile("org.springframework.boot:spring-boot-starter-web")
compile("org.apache.camel:camel-core:${camelversion}")
compile("org.apache.camel:camel-spring-boot:${camelversion}")
compile("org.apache.camel:camel-twitter:${camelversion}")
compile("org.apache.camel:camel-elasticsearch:${camelversion}")
compile("org.apache.camel:camel-jackson:${camelversion}")
compile("joda-time:joda-time:2.8.2")
testcompile("org.springframework.boot:spring-boot-starter-test")
}
请注意,根据
maxsize
和
batchsize
,代码要么执行返回单页结果的常规搜索,要么执行允许我们检索大量结果的
滚动
请求。在滚动的情况下,
searchhititerator
将在后续调用 elasticsearch 以批量检索结果。
安装弹性搜索
- 从 https://www.elastic.co/downloads/elasticsearch 下载 elasticsearch。
-
将其安装到本地文件夹 (
$es_home) -
编辑
$es_home/config/elasticsearch.yml并添加此行:cluster.name: tweet-indexer -
安装 bigdesk 插件来监控 elasticsearch:
$es_home/bin/plugin -install lukas-vlcek/bigdesk -
运行弹性搜索:
$es_home/bin/elasticsearch.sh或$es_home/bin/elasticsearch.bat
这些步骤将允许您以最少的配置运行一个独立的 elasticsearch 实例,但请记住它们不适合生产使用。
运行 应用程序
这是应用程序的入口点,可以从命令行运行。
def camelversion = '2.15.2'
dependencies {
compile("org.springframework.boot:spring-boot-starter-web")
compile("org.apache.camel:camel-core:${camelversion}")
compile("org.apache.camel:camel-spring-boot:${camelversion}")
compile("org.apache.camel:camel-twitter:${camelversion}")
compile("org.apache.camel:camel-elasticsearch:${camelversion}")
compile("org.apache.camel:camel-jackson:${camelversion}")
compile("joda-time:joda-time:2.8.2")
testcompile("org.springframework.boot:spring-boot-starter-test")
}
要运行该应用程序,请从您最喜欢的 ide 运行
application.main()
方法或从命令行执行以下行:
def camelversion = '2.15.2'
dependencies {
compile("org.springframework.boot:spring-boot-starter-web")
compile("org.apache.camel:camel-core:${camelversion}")
compile("org.apache.camel:camel-spring-boot:${camelversion}")
compile("org.apache.camel:camel-twitter:${camelversion}")
compile("org.apache.camel:camel-elasticsearch:${camelversion}")
compile("org.apache.camel:camel-jackson:${camelversion}")
compile("joda-time:joda-time:2.8.2")
testcompile("org.springframework.boot:spring-boot-starter-test")
}
一旦应用程序启动,它将自动开始索引推文。转到 http://localhost:9200/_plugin/bigdesk/#cluster 以可视化您的索引:
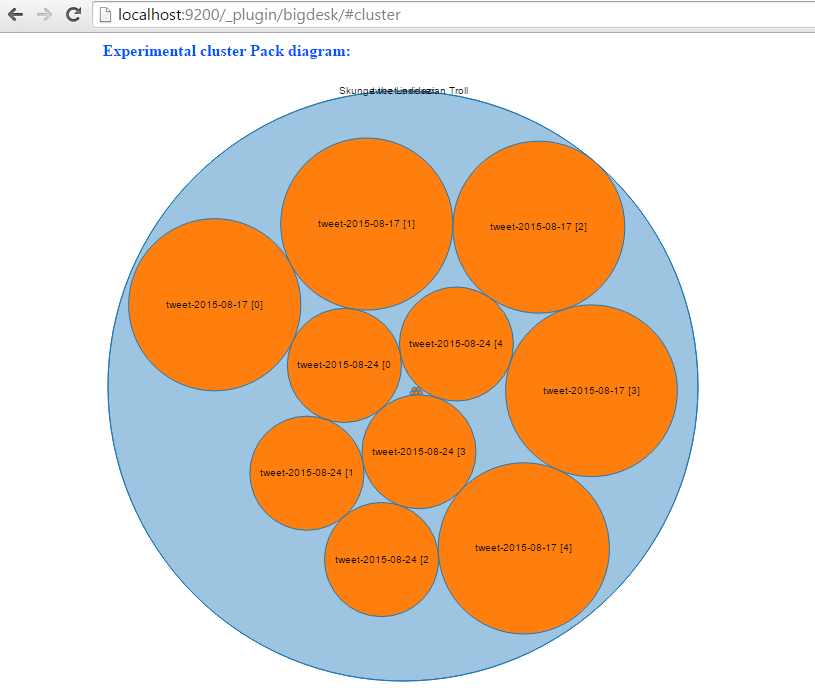
要搜索推文,请在浏览器中输入类似于此的网址: http://localhost:8080/tweet/search?q=toronto&max=100 。

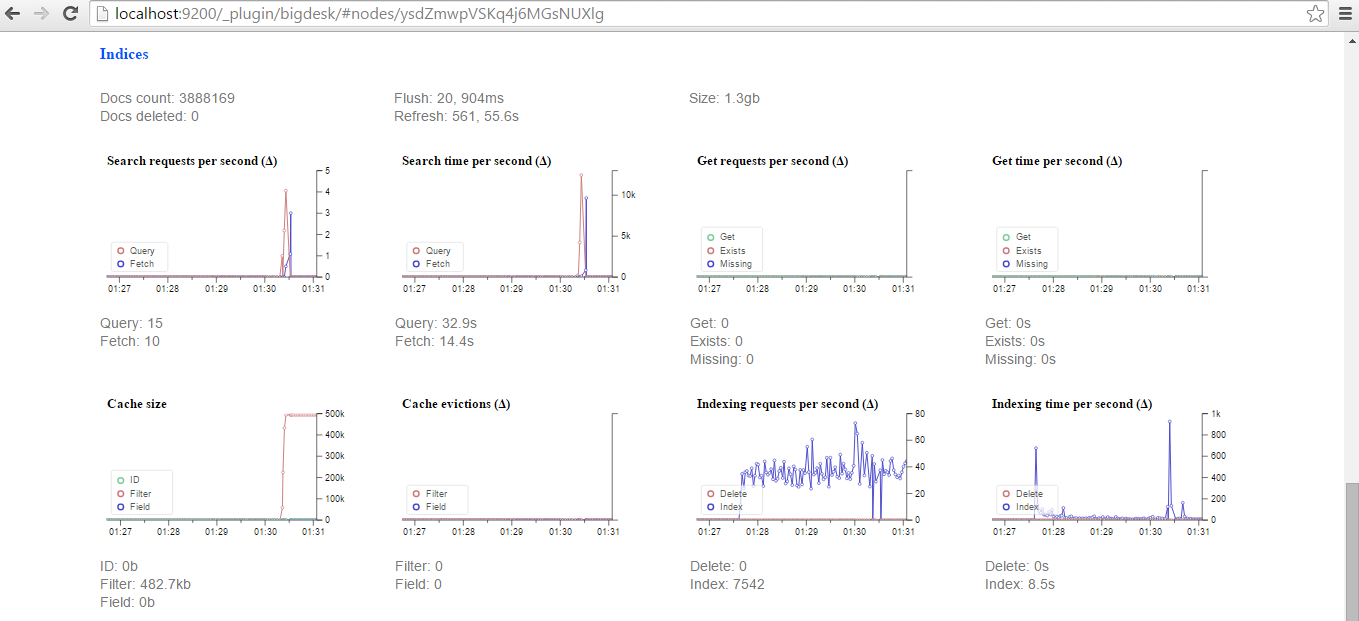
使用 bigdesk 插件,我们可以监控 elasticsearch 如何索引推文:
结论
在这个 apache camel 的介绍中,我们介绍了如何使用这个集成框架与外部组件(如 twitter 示例提要和 elasticsearch)进行通信,以实时索引和搜索推文。
示例应用程序的源代码可从 https://github.com/davidkiss/twitter-camel-ingester 获得。
您可能还会发现这篇文章很有趣: 如何在 5 分钟内开始使用 Storm 框架 。