 异常教程
异常教程
使用 Neo4j 解释 CSV 文件以在 WoW 中进行销售补偿
💡一则或许对你有用的小广告
欢迎加入小哈的星球 ,你将获得:专属的项目实战 / 1v1 提问 / Java 学习路线 / 学习打卡 / 每月赠书 / 社群讨论
- 新项目:《从零手撸:仿小红书(微服务架构)》 正在持续爆肝中,基于
Spring Cloud Alibaba + Spring Boot 3.x + JDK 17...,点击查看项目介绍 ;- 《从零手撸:前后端分离博客项目(全栈开发)》 2 期已完结,演示链接: http://116.62.199.48/ ;
截止目前, 星球 内专栏累计输出 82w+ 字,讲解图 3441+ 张,还在持续爆肝中.. 后续还会上新更多项目,目标是将 Java 领域典型的项目都整一波,如秒杀系统, 在线商城, IM 即时通讯,权限管理,Spring Cloud Alibaba 微服务等等,已有 2900+ 小伙伴加入学习 ,欢迎点击围观
复杂的销售组织中的薪酬计划和计算可能对传统数据库造成难以置信的负担。足够大的组织通常会在一夜之间将这些流程分批处理或变成每周一次的工作。
出于这篇博文的目的,让我们来看看 slashco:魔兽世界中最热门的多层次营销“公会”。 在此处获取此博客文章中使用的完整数据集和密码查询 。
![]()
在这个公会中,“伙伴”可以加入并向艾泽拉斯的许多人出售 slashco 的精美冒险装备,并招募他们的朋友和家人也出售 slashco 产品。当一名同事招募某人加入行会时,该新成员将成为该同事“下游”的一部分。作为引进这位新成员的特许权使用费,合作伙伴将从他们“下游”的成员出售的每件商品中收取少量佣金。
在这个薪酬计划中,我们有销售法师,他们既会直接销售产品,也会招募人员代表 slashco 销售产品。我创建了一个基于流行的多层次营销模型的示例模型。它包括四个收入来源:
- 直接销售: 对于团队成员直接销售的每件商品,他们都会赚取佣金。
- 下游特许权使用费: “下游”人员所售商品零售价的百分比,指的是他们招募为 slashco 工作的人员,以及他们招募的人员。
- 批发利润: 销售给“下游”的商品所赚取的百分比(这些商品随后将转售给消费者。
- 全球销售特许权使用费: slashco 内部人员的总销售额的百分比(又名收益分享)。
这是一个典型的传销组织如何补偿其员工的示例:

我们看到,根据您所处的级别,您获得直接销售和被动收入流的方式可能会有很大差异。因此,至少可以说,计算补偿金是一件很棘手的事情。
如果我们要从遗留的销售薪酬规划师迁移我们的数据,最好将所有数据推送到一系列 .csv 文件中。在数据库世界中,逗号分隔值文件通常是最小公分母——因此,对于我从事的 90% 的项目,我都是从那里开始的。
假设我们已将旧的 mysql 数据推送到一系列 3 个 .csv 文件中:
这些是理想化的转储,其中我将通常大约十几个 csv 文件合成为三个,只是为了展示数据在 neo4j 的 etl 过程( 加载 csv )之前和之后的外观示例。
当通过 excel 检查时(您也可以使用任何其他文本编辑器查看它们),我们将看到一系列标题和具有与这些标题对应的值的行。例如在下图中,我们可以看到 ID 为 1000000 的交易在“salesrepid”标题下的值为 30,在“period”标题下为 22,在“item1”标题下为 7780 等.等我们需要告诉 neo4j 如何将这些信息解释为一系列节点和关系,而不是正方形的“行和列”数据。

在我们实际将任何数据加载到 neo4j 之前,了解哪些问题对我们的业务很重要是很重要的。在这种情况下,我们正在为销售补偿工具建模。我们的热门查询可能是这样的:
- 根据薪酬规则,按期间支付给每个代表的佣金
- 根据薪酬规则每年向每位代表支付佣金
- 销售排行榜
- 总销售额最高的销售代表
- 最大交易的最佳销售代表
- 全球报告
- 按期间销售
- 畅销商品
- 建议
- 哪些物品最常一起出售?
当我们知道这些问题后,我们就可以构建一个模型,以便快速有效地回答这些问题。
作为一般规则, 如果一段数据对您的用例很重要,“使其物理化” 意味着,如果您要根据特定信息位进行遍历或过滤,则将其设为节点或关系。
例如:因为我们知道“交易”对我们的销售排行榜很重要,所以我们打算将交易(transaction)的想法作为一个特定类型的节点。然后我们将添加有关该交易的信息,例如交易发生的时间、所有者以及交易包含的项目。然而,作为“最后一步”,我们将对价格进行一些基本的数学运算,这是特定于该项目的——所以我们将把它保留为一个属性。
slaschco 销售补偿申请数据模型

我用来构建此示例的脚本位于 此 git repo 中。
现在我们有了一个数据模型,让我们启动 neo4j 并传入我们的导入脚本( 在此处找到 )。本质上我们正在做的是创建一些约束和索引,然后告诉 neo4j 如何将我们的 csv 文件解释为上述模型。

现在我们已经加载了所有数据,让我们打开浏览器并开始回答一些热门查询。

我们会逆向工作
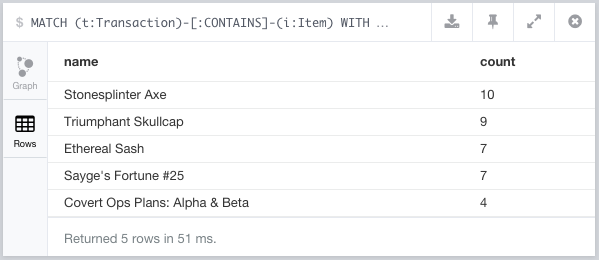
5.推荐
- 哪些物品最常一起出售?
//recommendation engine, what items are most frequently co-sold?
match path = (item:item)-[:contains]-(:transaction)-[:contains]-(item2:item)
where id(item) > id(item2)
with item, item2, count(distinct path) as instances
order by instances desc
limit 3
return item.name, item2.name, instances;

4. 全球报告
- 按期间销售
- 畅销商品
//recommendation engine, what items are most frequently co-sold?
match path = (item:item)-[:contains]-(:transaction)-[:contains]-(item2:item)
where id(item) > id(item2)
with item, item2, count(distinct path) as instances
order by instances desc
limit 3
return item.name, item2.name, instances;

//recommendation engine, what items are most frequently co-sold?
match path = (item:item)-[:contains]-(:transaction)-[:contains]-(item2:item)
where id(item) > id(item2)
with item, item2, count(distinct path) as instances
order by instances desc
limit 3
return item.name, item2.name, instances;
3.销售排行榜
- 总销量最高的销售代表
- 最大交易的最佳销售代表
//recommendation engine, what items are most frequently co-sold?
match path = (item:item)-[:contains]-(:transaction)-[:contains]-(item2:item)
where id(item) > id(item2)
with item, item2, count(distinct path) as instances
order by instances desc
limit 3
return item.name, item2.name, instances;

//recommendation engine, what items are most frequently co-sold?
match path = (item:item)-[:contains]-(:transaction)-[:contains]-(item2:item)
where id(item) > id(item2)
with item, item2, count(distinct path) as instances
order by instances desc
limit 3
return item.name, item2.name, instances;

2. 每年根据薪酬规则向每位代表支付佣金
由于查询的复杂性,我决定将每个级别的代表分成自己的查询来运行它们,但是它们都遵循“我如何处理所有这些黄金”查询的基本形式:
//recommendation engine, what items are most frequently co-sold?
match path = (item:item)-[:contains]-(:transaction)-[:contains]-(item2:item)
where id(item) > id(item2)
with item, item2, count(distinct path) as instances
order by instances desc
limit 3
return item.name, item2.name, instances;

1. 每位代表的佣金,根据薪酬规则按期限支付
这看起来与我们上一个查询非常相似,只是我们添加了一个短模式
(transaction)-[:occurred_in]-(period {period:35})
这将过滤掉发生在非第 35 个期间的所有交易。我们仍然可以看到,在一个合理大小的数据集(100 名员工、2 万个项目、1 万笔交易)中,neo4j 快如闪电。
//recommendation engine, what items are most frequently co-sold?
match path = (item:item)-[:contains]-(:transaction)-[:contains]-(item2:item)
where id(item) > id(item2)
with item, item2, count(distinct path) as instances
order by instances desc
limit 3
return item.name, item2.name, instances;

//kvg
【 作为社区内容,本文仅代表作者个人观点,不代表neo4j官方立场。这篇文章最初是由 kevin van gundy 在 kevin van gundy 的博客 上写的。 ]