图 1 显示了结构良好的程序包的 spoiklin 类图 。
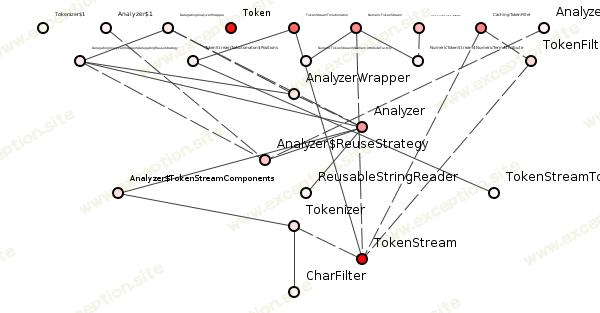
图 1:来自 Lucene 的良好包结构。
它结构良好,因为它使依赖关系跟踪相对容易。如果我们随机选择一个类——比如 ReusableStringReader—— 我们可以很容易地发现对该类的依赖,从而估计对该类所做更改的潜在成本,见图 2。

图 2:跟踪 ReusableStringReader 上的依赖项。
然而,依赖性有两种形式。语法依赖不依赖于连接节点名称的含义。然而,语义依赖性确实如此。图 2 的依赖关系是否也是良好的语义依赖关系?
要回答这个问题,我们必须检查从属类的名称并询问它们是否“有意义”,因为在它们各自的认识论领域内可能期望这些名称之间存在联系。
因此,我们有一个依赖于 ReusableStringReader 的 分析器 。这是有道理的;如果您正在构建功能来分析某些东西,您可能很想读取字符串,而“可重用”字符串读取器听起来像是一种特定类型的字符串读取器,因此这种语义依赖性不足为奇。同样, AnalyzerWrapper 很可能依赖于 Analyzer 。重复这个练习可以揭示出一个合理的语义结构。
结构是一组节点及其互连,那么哪个更重要:句法结构还是语义结构?
让我们更改图 2 以故意降低其语义结构。
纯粹的语法更改涉及更改节点之间的依赖关系。纯粹的语义更改涉及更改节点的名称(添加或删除节点既是句法更改也是语义更改)。因此,让我们通过将 ReusableStringReader 的名称更改为 Banana 来进行最小的语义修改。

图 3:语义失误。
“Banana”是 ReusableStringReader 类的一个可怕的名字。试图理解这个包的程序员看到分析功能依赖于水果(或草本植物,或香蕉是什么)时会哭泣。猴子依赖香蕉,而不是分析功能。这是糟糕的语义结构。
但是,如果我们更改 Banana 中的代码,我们仍然可以预测潜在的连锁反应吗?是的,我们可以,因为涟漪效应通过句法而不是语义依赖传播。即使我们删除所有语义信息(见图 4),我们也可以追踪可能受影响的类。
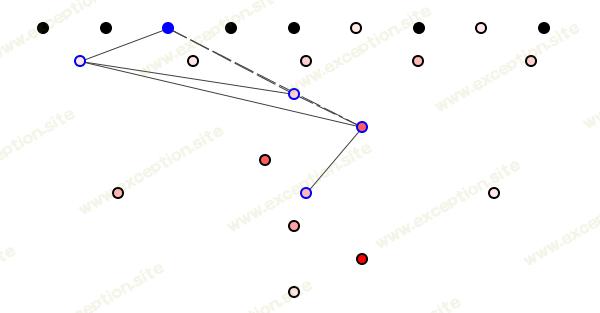
图 4:无语义图。
或者,我们可以检查语法结构糟糕的包并改进其语义以衡量整体收益。图 5 显示了这种不良封装。
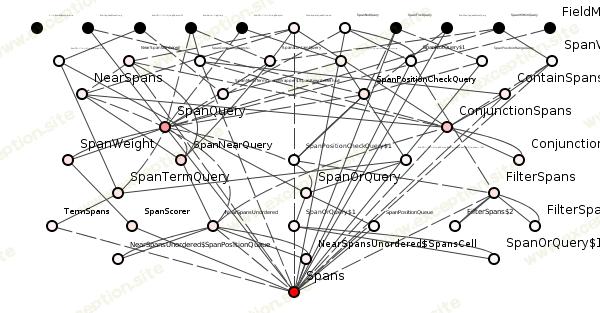
图 5:来自 Lucene 的一个可怕的包。
除非我们不尝试语义改进。
因为即使 Wittgenstein 和 Chomsky 自己将图 5 结对编程到软件工程史上最著名的软件包中,估算变更成本仍然是一场噩梦。
概括
良好的软件结构的主要目的是帮助影响成本估算,并间接地降低实际影响成本。语义是一种重要的理解辅助工具,但与由优秀句法结构支持的语义水果篮相比,在糟糕的句法结构上覆盖语义健全性的更新成本更高。
语法 bitch-slap 语义。
难的。