 异常教程
异常教程
只需 3 分钟即可将 1000 万个 Stack Overflow 问题导入 Neo4j
💡一则或许对你有用的小广告
欢迎加入小哈的星球 ,你将获得:专属的项目实战(已更新的所有项目都能学习) / 1v1 提问 / Java 学习路线 / 学习打卡 / 每月赠书 / 社群讨论
- 新开坑项目:《Spring AI 项目实战》 正在持续爆肝中,基于 Spring AI + Spring Boot 3.x + JDK 21..., 点击查看 ;
- 《从零手撸:仿小红书(微服务架构)》 已完结,基于
Spring Cloud Alibaba + Spring Boot 3.x + JDK 17...,点击查看项目介绍 ;演示链接: http://116.62.199.48:7070 ;- 《从零手撸:前后端分离博客项目(全栈开发)》 2 期已完结,演示链接: http://116.62.199.48/ ;
截止目前, 星球 内专栏累计输出 100w+ 字,讲解图 4013+ 张,还在持续爆肝中.. 后续还会上新更多项目,目标是将 Java 领域典型的项目都整一波,如秒杀系统, 在线商城, IM 即时通讯,权限管理,Spring Cloud Alibaba 微服务等等,已有 3700+ 小伙伴加入学习 ,欢迎点击围观
我想演示如何获取堆栈溢出转储并将其快速导入到 Neo4j 中。之后,您就可以开始查询图表以获得更多见解,然后可能会在该数据集之上构建应用程序。如果你想继续,我们有一个正在运行的(只读的)neo4j 服务器 ,这里有可用的 数据。
但首先要做的是: 祝贺 stack overflow 如此出色和乐于助人。他们最近刚刚宣布在他们的网站上已经回答了超过一千万个编程问题(并且还在增加)。 (他们还围绕 #soreadytohelp 主题标签做赠品。更多内容见下文。)
如果没有 stack overflow 平台,许多关于 neo4j 的 问题将永远不会被提出或回答。我们仍然很高兴我们开始摆脱 google groups 以获得公共用户支持。
stack overflow 上的 neo4j 社区 增长了很多,那里的问题数量也增加了。

(这是一个图表)
将堆栈溢出数据导入 neo4j
将数以百万计的堆栈溢出问题、用户、答案和评论导入 neo4j 一直是我的长期目标。阻止我这样做的干扰之一是回答 那里的 8,200 个 neo4j 问题中的 许多问题。
两周前, linkurious 的 达米恩 在 我们的公共 slack 频道 中联系了我。他询问了 neo4j 将完整堆栈交换数据转储摄取到 neo4j 的导入性能。
快速讨论后,我向他指出了 neo4j 的 csv 导入工具 ,该工具非常适合该任务,因为转储仅包含用 xml 包装的关系表。
因此,damien 编写了一个小的 python 脚本来从 xml 中提取 csv,并使用必要的标头,neo4j-import 工具完成了从巨大的表格中创建图形的繁重工作。您可以 在此处的 github 上找到脚本和说明 。
导入较小的堆栈交换社区数据只需要几秒钟。令人惊讶的是,包含用户、问题和答案的完整堆栈溢出转储需要 80 分钟才能转换回 csv,然后 只需 3 分钟 即可在带有 ssd 的普通笔记本电脑上导入 neo4j。
这是我们如何做到的:
下载堆栈交换转储文件
首先,我们 从 Internet 存档中为 stack overflow 社区下载了转储文件 (总共 11 GB)到一个目录中:
- 7.3g stackoverflow.com-posts.7z
- 576k stackoverflow.com-tags.7z
- 154m stackoverflow.com-users.7z
如果我们想要,其他数据可以单独导入:
- 91m stackoverflow.com-badges.7z
- 2.0g stackoverflow.com-comments.7z
- 36m stackoverflow.com-postlinks.7z
- 501m stackoverflow.com-votes.7z
解压缩 .7z 文件
for i in *.7z; do 7za -y -oextracted x $i; done
这会将文件提取到
extracted
目录,需要 20 分钟,并在磁盘上使用 66gb。
克隆 damien 的 github 存储库
下一步是克隆 damien 的 github 存储库:
for i in *.7z; do 7za -y -oextracted x $i; done
注意:此命令使用 python 3 ,所以你必须安装
xmltodict
for i in *.7z; do 7za -y -oextracted x $i; done
运行 xml 到 csv 的转换
之后,我们将 xml 转换为 csv。
for i in *.7z; do 7za -y -oextracted x $i; done
转换在我的系统上运行了 80 分钟,生成了 9.5gb 的 csv 文件,这些文件被压缩到 3.4g。
这是导入到 Neo4j 中的数据结构。 csv 文件的标题行提供映射。
节点:
for i in *.7z; do 7za -y -oextracted x $i; done
关系:
for i in *.7z; do 7za -y -oextracted x $i; done
导入 neo4j
然后我们使用 neo4j 导入工具
neo/bin/neo4j-import
摄取帖子、用户、标签以及它们之间的关系。
for i in *.7z; do 7za -y -oextracted x $i; done
实际导入只需要 3 分钟,创建一个 18 GB 的图形存储。
for i in *.7z; do 7za -y -oextracted x $i; done
neo4j 配置
然后我们想调整 neo4j 的配置
conf/neo4j.properties
增加
dbms.pagecache.memory
选择10g。我们还编辑了
conf/neo4j-wrapper.conf
提供更多的堆,例如 4g 或 8g。
然后我们启动了neo4j服务器
../neo/bin/neo4j start
添加索引
然后我们可以选择直接在 neo4j 的服务器 ui 或命令行上运行下一个查询
../neo/bin/neo4j-shell
它连接到正在运行的服务器。
这是我们在那里有多少数据:
for i in *.7z; do 7za -y -oextracted x $i; done
接下来,我们创建了一些索引和约束供以后使用:
for i in *.7z; do 7za -y -oextracted x $i; done
然后我们等待索引完成。
for i in *.7z; do 7za -y -oextracted x $i; done
请注意:neo4j 作为图形数据库最初并不是为这些全局聚合查询构建的。这就是为什么响应不是即时的。
通过密码查询获得见解
以下只是我们使用密码查询从堆栈溢出数据中收集到的一些见解:
前 10 个堆栈溢出用户
for i in *.7z; do 7za -y -oextracted x $i; done
jon skeet 在提问时使用的前 5 个标签
似乎他从来没有真正问过问题,而只是回答过。
for i in *.7z; do 7za -y -oextracted x $i; done
balusc 回答的前 5 个标签
for i in *.7z; do 7za -y -oextracted x $i; done
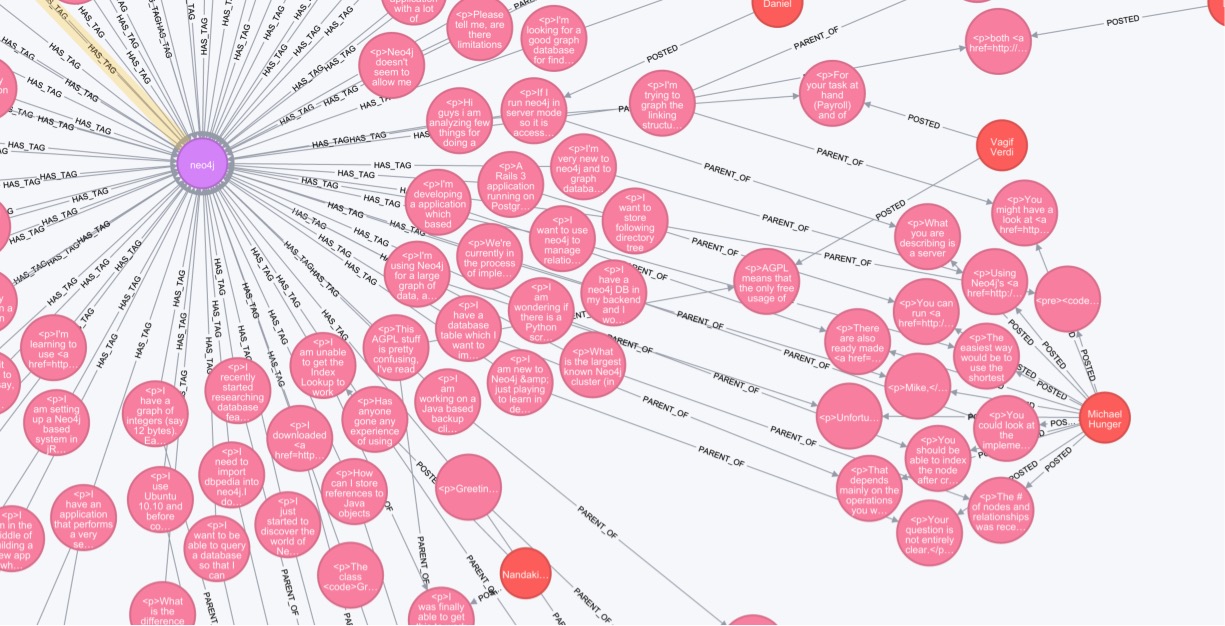
我如何连接到 darin dimitrov?
for i in *.7z; do 7za -y -oextracted x $i; done
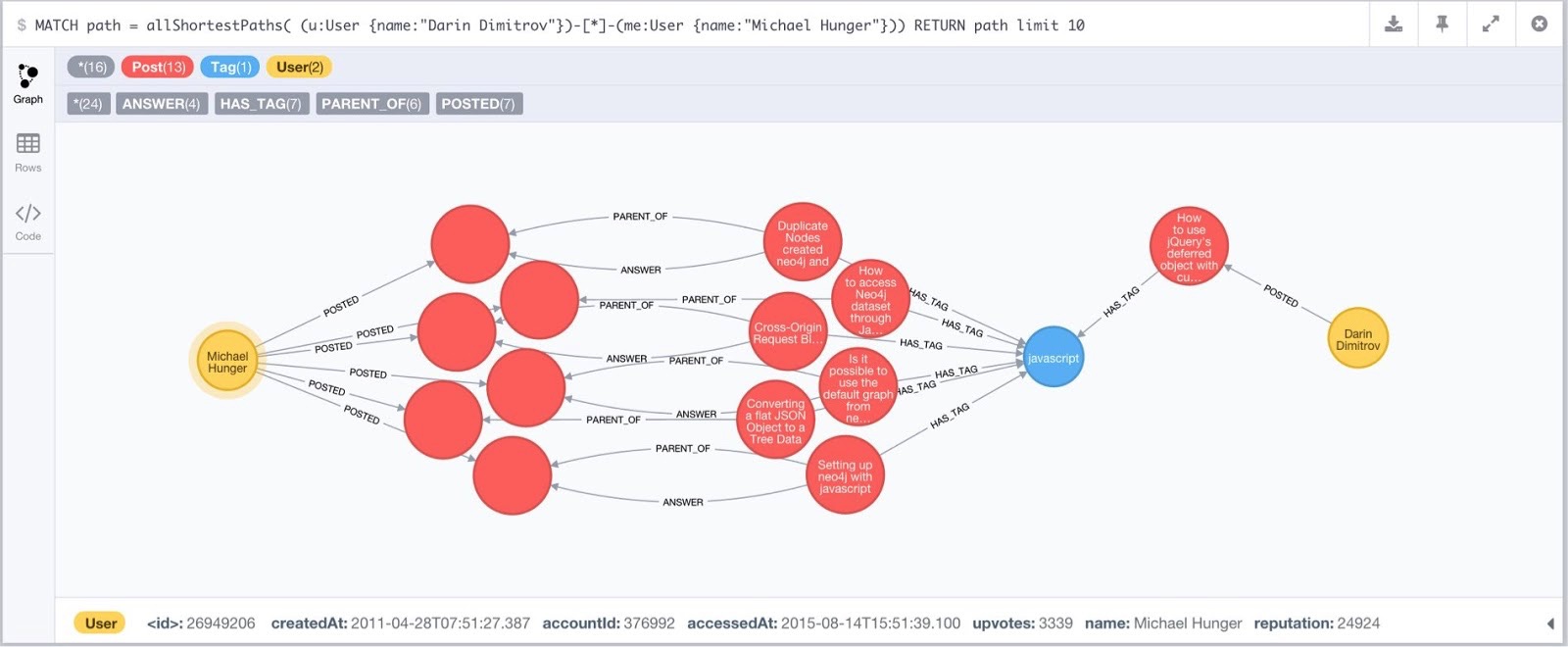
Neo4j 浏览器中的结果可视化
哪个 标记 回答了最多关于 neo4j 的问题?
for i in *.7z; do 7za -y -oextracted x $i; done

呈现为图形的前 20 条路径
有史以来排名前 5 位的标签
for i in *.7z; do 7za -y -oextracted x $i; done
javascript 标签的共现
for i in *.7z; do 7za -y -oextracted x $i; done
neo4j 标签最活跃的回答者
顺便说一句: 感谢 所有回答 neo4j 问题的人!
for i in *.7z; do 7za -y -oextracted x $i; done
最佳回答者还有哪些地方也很活跃?
for i in *.7z; do 7za -y -oextracted x $i; done
请注意,上面的这个密码查询包含相当于 14 个 sql 连接。
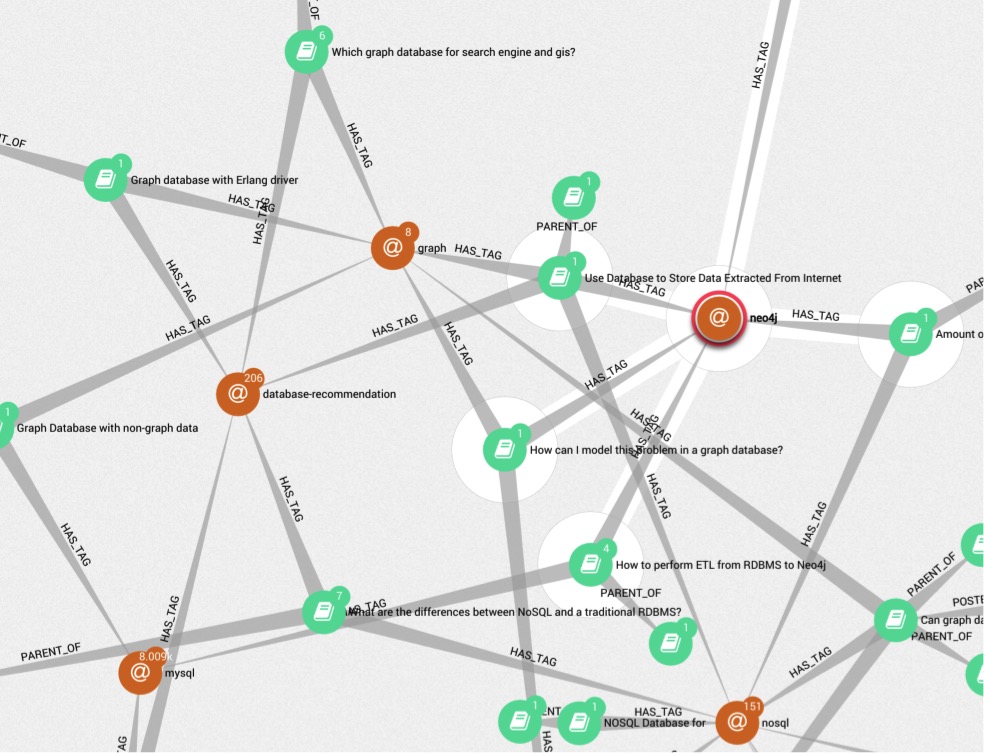
在 linkurious visualizer 中呈现
发布有关 neo4j 问题最多的人
for i in *.7z; do 7za -y -oextracted x $i; done
py2neo 标签的最佳回答者
for i in *.7z; do 7za -y -oextracted x $i; done
哪些用户回答了他们自己的问题
这个全局图形查询需要一点时间,因为它涉及数据库中的 2 亿条路径,它会在大约 60 秒后返回。
如果您只想对 450 万用户的一个子集执行它,您可以添加过滤条件,例如信誉。
for i in *.7z; do 7za -y -oextracted x $i; done
更多信息
我们很高兴在这里为您提供堆栈溢出转储的图形数据库:
- 2.3 快照 或 2.2.4 的 neo4j 数据库转储
- 运行 neo4j 服务器来探索数据 (只读)
- .csv 文件
如果您想了解在 Neo4j 中导入或可视化堆栈溢出问题的其他方法,请查看这些博客文章:
- 从 url 加载 json 作为数据
- 使用 Neo4j 让主数据管理变得有趣
- 可视化堆栈溢出
- 拥抱与 Neo4j、R 和 Java 的关系
- 另请查看 堆栈溢出开发人员调查 。这是一本非常有趣的书。
再次感谢所有发布和回答 neo4j 问题的人。你们是让 neo4j 社区真正活跃起来的人,如果没有你们,这种级别的分析只会有一半的乐趣。
回到堆栈溢出的 1000 万个问题里程碑,感谢您 #soreadytohelp 与 neo4j 和 cypher 相关的任何堆栈溢出问题。
如果您在此数据集上发现其他有趣的问题和答案,请告诉我们。只需给我们发送电子邮件至 content@neo4j.com 。